
한빛미디어 도서 <혼자 공부하는 머신러닝+딥러닝>의 전개를 따른 내용이다.
챕터 7, 딥러닝을 시작합니다!
* 딥러닝의 핵심 알고리즘 '인공 신경망'
* 대표적인 인공 신경망 라이브러리 텐서플로, 케라스
* 인공 신경망 모델의 훈련을 돕는 도구 익히기
[ 주저리.. ]
패션 아이템 데이터셋 (fashion_mnist)로 실습했다.
데이터셋의 이미지를 슬쩍 보니까 아주 예쁜 킬힐이 보이네 갖고싶게두...
물론 난 킬힐에 아주 미숙하지만...
어떻게 하면 킬힐을 신고 잘 걸어다닐 수 있는지 모르겠다..

데이터 준비
훈련 데이터 : 60000개의 28*28 이미지
타겟 데이터 : 60000개의 1차원 배열
테스트 데이터 : 10000개의 28*28 이미지
테스트 타깃 : 10000개의 1차원 배열
사용할 이미지 데이터 확인:
( 앞 10개 데이터 )
각 패션 이미지의 레이블 :
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 티셔츠 | 바지 | 스웨터 | 드레스 | 코트 | 샌달 | 셔츠 | 스니커즈 | 가방 | 앵클부츠 |
각 레이블당 샘플 개수 확인 :
# 로지스틱 회귀모델의 분류 성능
※ 인공신경망 분류모델을 만들기 전에, 확률적 경사하강법을 사용하는 로지스틱 회귀모델의 성능 먼저 확인해볼 것이다.
로지스틱 회귀모델
- 먼저 이미지 데이터를 정규화!
( 특성마다 값의 범위가 크게 다르지 않도록 정규화하자. 확률적 경사 하강법을 통해 특성 중 기울기가 가파른 방향으로 이동하므로, 공정히 모든 특성을 정규화해야 한다. )
이미지 데이터의 0~255 값을 0~1 값으로 정규화하는 방식이 많이 쓰인다.
- SGCClassifier는 1차원 배열을 다룬다는 것을 기억!
28*28 이미지를 1차원 배열로 변환하자.
- 교차검증 결과 :
문제점 : max_iter를 더 크게 조정해도 성능이 많이 개선되지 않는다.
개선 방법 : 인공 신경망
# 인공 신경망
선형회귀식 결과로 클래스를 분류하는 것은 아래 그림으로 표현 가능하다.
로지스틱 회귀모델에서 학습한 회귀식(가중치, 절편)을 통해 z1~zk로 분류할 수 있다. (소프트맥스 함수를 통하여 각 클래스별 확률을 얻을 수 있었음을 기억! )
이를 인공신경망의 용어로 이해해보자.
각각의 n개 입력층은, z1~zk를 만드는 가중치와 절편를 통하여 특정 출력층을 만들어낸다.
예) 출력층 z1을 만들기 : 입력층 n개는 가중치 w_1.1 ~ w_n.1와 절편 b_1을 거쳐서 출력층 z1을 만든다.
각 출력층을 만드는 어떤 연산단위를 '뉴런' or '유닛' 이라고 부른다.
cf) 이미지 데이터의 경우 입력층의 데이터는 각각의 픽셀이 된다.
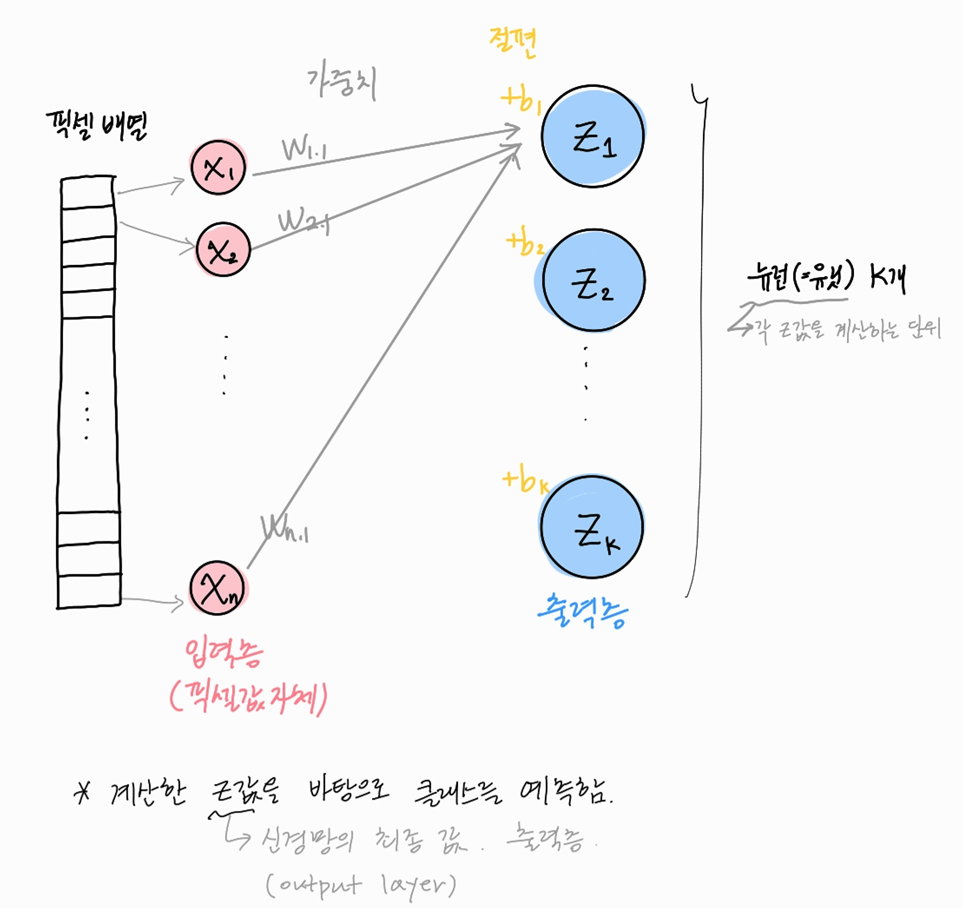
왜 인공신경망이 위와 같은 그림으로 표현되는지는 대충 이런 느낌으로 이해하면 될 것 같다.
이러한 인공신경망이 여러 층이 모이면 심층 신경망(DNN, deep neural network)이며, 딥러닝으로 이어진다.
( 참고 : 생물학적 뉴런의 수상돌기는 신호를 받고, 신호가 세포체에 모이고, 신호가 어떤 임계치에 도달하면 축삭돌기를 통해 다른 세포에 신호를 전달한다 )
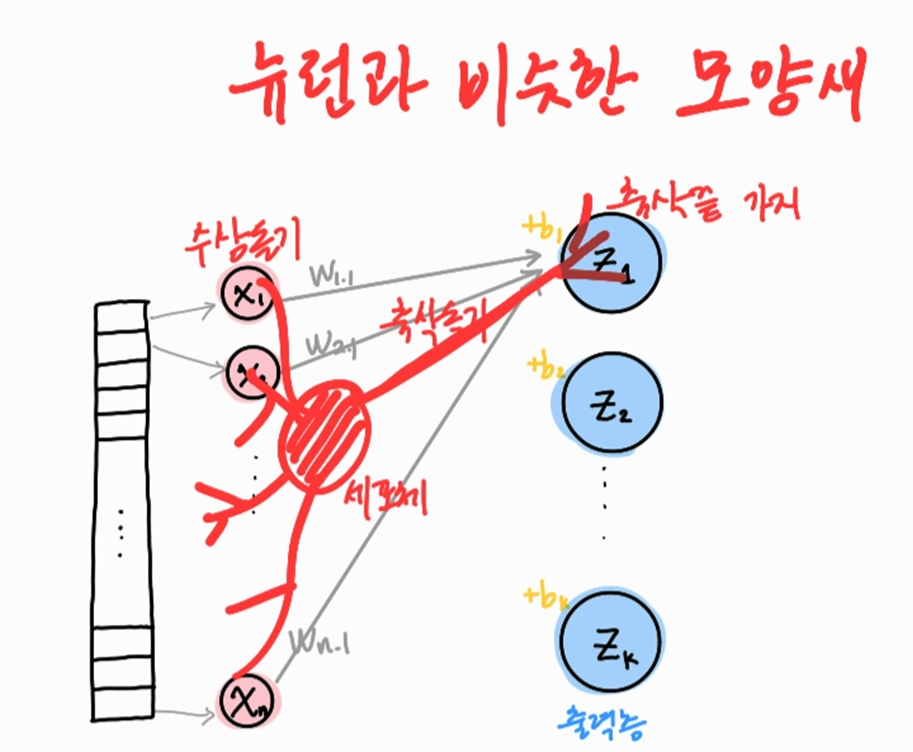
# 인공 신경망 모델 만들기
구글 텐서플로의 고수준 API인 케라스를 사용할 것이다.
딥러닝 라이브러리는 GPU를 사용해 인공신경망을 훈련한다.
케라스는 직접 GPU를 사용하지는 않고, GPU연산을 사용하는 텐서플로를 백엔드로 사용한다.
cf) GPU는 벡터, 행렬 연산에 매우 최적화됨!
1. 훈련세트, 검증세트 만들기
인공신경망은 보통 교차검증을 하지 않고 검증세트를 따로 만든다.
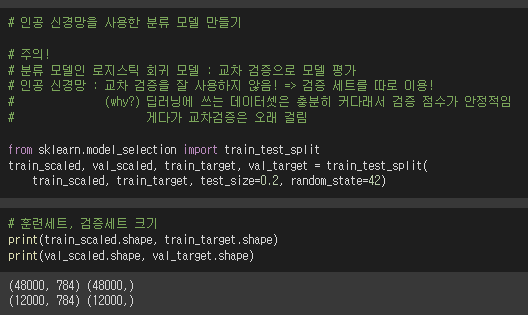
2. layers 만들기
keras.layers 패키지에는 다양한 layer가 준비되어있다.
그 중 dense layer(밀집층)라는 fully connected layer를 만들어보자.
총 10개의 클래스로 분류할 것이기 때문에 10개의 뉴런으로 구성할 것이다.
그러면 28*28=784개의 픽셀 데이터와 10개의 클래스가 fully connected되어 7840개의 연결선이 생긴다.

- 인공신경망으로 분류 모델을 만들고 있기 때문에 activation에는 softmax함수를 지정한다.
(다중분류모델임을 기억! softmax함수는 출력값을 각 클래스에 대한 확률로 바꿔준다)
(이중분류모델이었다면 sigmoid 함수를 사용했음을 기억!)
3. layer를 가지는 인공신경망 모델 만들기
keras.Sequential을 사용하였다.
(신경망 모델을 만드는 클래스임)

4. 인공신경망 모델 훈련하기
keras를 통해서, 어떤 layer를 가진 이 인공신경망 모델을 만들었다.
이제 이 케라스 모델을 훈련시킬 차례다.
※ 케라스 모델을 훈련하기 전에 '설정'이 필요하다.
compile() 메서드를 통해 여러 하이퍼 파라미터를 설정할 수 있다.
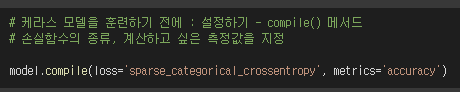
[ metrics 매개변수 ]
모델은 loss를 점점 줄이는 방향으로 학습하기에, 기본적으로 epoch마다 손실값을 보여준다.
모델이 loss를 줄여나가면 모델이 정확도를 높이면서 잘 학습하고 있다는 것!
이런 정확도를 같이 보고 싶으면 metrics='accuracy'를 지정한다.
[ 손실 함수 ]
* 이진 분류: 이진 크로스 엔트로피 손실 함수 사용
=> keras의 'binary_crossentropy'
cf. 이진 크로스 엔트로피 복습
이진 크로스 엔트로피
출력층이 (sigmoid를 통해) a라는 확률 값(0~1)을 내놓았을 때 손실함수 값은,
§ 양성 샘플 : -log(a) * target값
§ 음성 샘플 : -log(1-a) * target값
이진 분류 모델에서는 양성 클래스에 대한 손실함수 값을 최소화하는 가중치와 절편을 학습해나간다는 것을 기억!
* 다중 분류: 크로스 엔트로피 손실 함수 사용
=> keras의 'categorical_crossentropy'
이 손실함수에 대한 설명 보기
샘플이 z_i 클래스일 확률을 a_i라고 하자 (i = 1, ..., n)
이때 크로스 엔트로피는
-log(a_i) * target값
그러면, target==1인 샘플에 해당하는 확률만 도출된다.
( 나머지 샘플은 target==0이므로 크로스 엔트로피가 0임 )
- 예시 -
target값이 1, 2, 3, 4 이렇게 총 4개 있는 상황에서,
어떤 샘플의 target값이 2일 경우를 생각해보자.
그럼 아래 배열처럼 표현 가능하다. 두번째 인덱스를 활성화하면 된다.
[0, 1, 0, 0]
(이런 표현을 one-hot encoding이라고 한다.)
그럼 해당 샘플에 대해 아래와 같은 배열 연산이 수행된다.
[a1, a2, a3, a4] * [0, 1, 0, 0] = [0, a2, 0, 0]
이 뉴런의 활성화 출력 : a2
크로스 엔트로피 : -log(a2) * 1
이 활성화 출력 값(확률)을 1에 최대한 가깝게 만들어야 한다.
=> 이 샘플의 target==2일 확률이 1에 가깝도록 학습해야 한다.
이를 통해 크로스 엔트로피 손실함수 값을 낮추는 것이 인공신경망 분류 모델의 학습 목적이다.
=> 그러나 이번 실습에서는 손실함수를 'sparse_categorical_crossentropy'로 사용했다.
sparse는 왜 붙은 것일까?
이 손실함수에 대한 설명 보기
다중분류 모델에 사용하는 샘플의 target값은 0, 1, 2, ... 처럼 정수로 구분되어진다.
그런데 다중 분류의 cross entropy를 계산하는 과정에서
샘플의 target값만을 1로 두고 나머지 target값은 0으로 두는 '원-핫 인코딩'을 사용했다. (이전 접은글 참고)
target값을 '원-핫 인코딩'으로 준비했을 경우에 categorical_crossentropy를 loss로 두면 된다.
그러나 텐서플로에서는 정수로된 target값을 그대로 사용해 cross entropy를 계산할 수 있다!
이것이 'sparse_categorical_crossentropy' 손실함수다.
[ 옵티마이저 ]
케라스는 다양한 경사 하강법 알고리즘을 지원한다.
이를 optimizer라고 한다.
기본값: RMSprop
( 적절한 optimizer를 설정하면 성능을 높일 수 있다)
.
.
케라스 모델을 compile(loss, matrics) 했으니,
훈련하기 위한 준비 끝!
fit하자!
훈련 세트에 대한 정확도가 0.8550으로 마무리되었다.
검증 세트에 대한 정확도는 0.848정도이다.
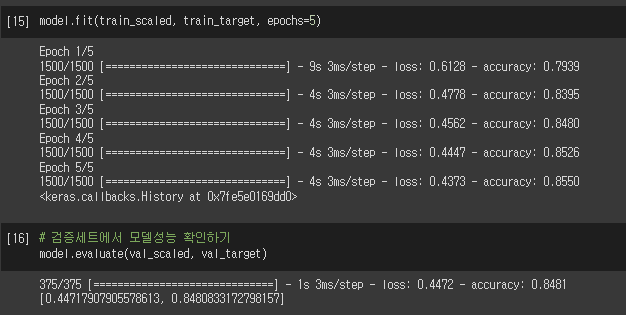
인공신경망 모델이 로지스틱 회귀모델보다 분류 정확도가 높다!
왜 그럴까?
그건 다음 절에서 말해준다고 한다.
챰.. 전부터 느낀건데
한빛미디어의 혼자 공부하는 머신러닝+딥러닝 이 책은 정말 밀당킹이다.
.
.
이런 상황이 참 많다
① 우와~! 이 모델 킹왕짱이다 댑악신기..
=> 그치만... 부족한 부분이 있기에 다음 절에서 얘기하겠다.
② 움... 근데 왜 이게 더 좋다는 건지는 설명 안해주시네..?
=> 그것은... 다음 절에 나온다.
.
.
그래서 참 재밌게 공부할 수 있는 매력적인 책인듯.. ㅋㄷㅋㄷ
아무튼 저는 강추합니다
다음 글:
딥러닝 | 딥러닝 모델 성능 높이기 | layer 추가 & 활성화함수 & 옵티마이저 조정하기
'데이터분석과 머신러닝' 카테고리의 다른 글
| 딥러닝 | 과대적합 피하기 | optimizer, dropout (+콜백) (0) | 2022.02.26 |
|---|---|
| 딥러닝 | 딥러닝 모델 성능 높이기 | layer 추가 & 활성화함수 & 옵티마이저 조정하기 (0) | 2022.02.25 |
| [python] k-means clustering visualization module | how to make scatterplot, gif (0) | 2022.02.17 |
| 혼공단 7기 5주차 미션인증 (0) | 2022.02.17 |
| 머신러닝 | 주성분분석(PCA)을 이미지 데이터에 적용하여 픽셀 축소하기 (0) | 2022.02.17 |