한빛미디어 도서 <혼자 공부하는 머신러닝+딥러닝>의 전개를 따른 내용이다.
챕터 7, 딥러닝을 시작합니다!
* 딥러닝의 핵심 알고리즘 '인공 신경망'
* 대표적인 인공 신경망 라이브러리 텐서플로, 케라스
* 인공 신경망 모델의 훈련을 돕는 도구 익히기
딥러닝 모델의 성능을 높이기 위해서는
- layer를 추가하기
- 적절한 활성화함수 사용하기
- 적절한 옵티마이저 사용하기
를 고려해볼 수 있다.
케라스의 도움을 받아서 순서대로 실습해볼 것이다.

데이터셋 준비

# layer 추가하기
인공 신경망이 여러 층 모이면 심층 신경망이 된다. => 딥러닝!
지난 번에는 오로지 입력층, 출력층만 있는 인공신경망을 만들었다.
이번에는 그 사이에 은닉층(hidden layer)를 추가해볼 것이다.

ⓐ 층 추가 방법 1
layer 객체를 생성하여 Sequential 클래스에 전달하기.

ⓑ 층 추가 방법 2
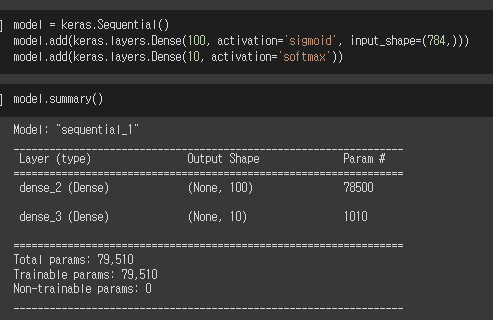
layer 객체를 따로 만들지 않고, Sequential 클래스의 생성자에서 바로 layer 생성하기
(어차피 layer는 따로 저장해 쓸 일이 없으므로 그냥 Sequential 안에서만 생성해 쓰자는 것임)
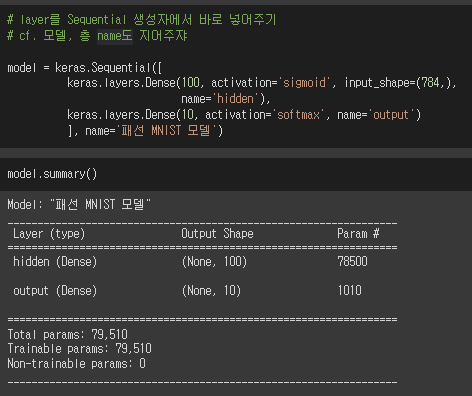
ⓒ 층 추가 방법 3
Sequential 클래스에 layer 추가시 가장 많이 사용되는 방법 : add() 메서드
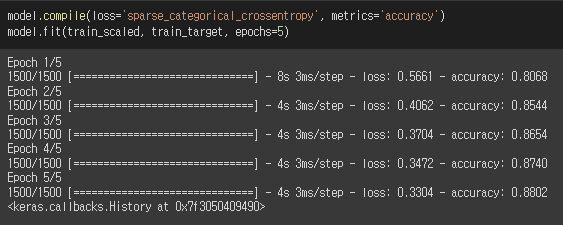
# 여러 layer를 가진 모델 훈련해보기
훈련 결과,
추가된 layer가 모델의 성능을 높였다!
▶ 층을 두개 더 추가해서 테스트해볼까?
그냥 무작정 추가한다고 성능이 높아지지는 않는다.
그렇다면 이미지 분류 모델에서는 layer에 어떤 활성화 함수를 사용해야 성능을 높일 수 있을까?

# ReLU 함수를 hidden layer에 추가해보자
relu 함수는 이미지를 처리하는 모델에 굿이라고 한다.
이전처럼 hidden layer에 sigmoid를 사용했을 시 단점 :
ㄴsigmoid를 사용하는 층이 누적될수록 출력을 왜곡시키는 현상이 커진다.
이를 개선하는 활성화 함수 : ReLU
z값이 양수면 z값 그대로를 출력한다.
0 이하는 0으로 출력한다.

hidden layer의 활성화함수로 relu를 사용하는 모델 만들기
*Flatten층은 그저 입력차원을 일렬로 펼쳐주는 역할로, 입력층 바로 뒤에 추가한다.
그러므로 모델을 fit할 때 굳이 일차원 배열을 넣어주지 않아도 된다.

sigmoid를 사용했을 때 vs relu를 사용했을 때를 비교해보자.

| 훈련 세트 점수 | 검증 세트 점수 | |
| sigmoid 사용 | 0.880 | 0.871 |
| relu 사용 | 0.887 | 0.873 |
웅? relu를 쓰면 이미지 처리에 더 적절해서 모델의 성능이 향상되어야 맞다.
실습해보니 훈련세트의 점수는 relu를 사용한 쪽이 높긴 하지만,
검증세트의 점수는 오히려 sigmoid를 사용한 쪽이 더 높다.
사실 모델 훈련은, 이번 훈련이 잘 되었냐 못 되었냐의 운도 있을 것이다.
(랜덤 배치를 사용하기 때문)
그래서 단편적인 한 결과를 봐서는 안되겠지..?!
아무튼 relu는 이미지 데이터 처리에 효과가 좋다고 한다.
- sparse하다는 특징 -
sparse의 반대는 dense하다는 것인데, sigmoid가 그러하다.
sigmoid는 0에 가까운 값이라도 0.0xx 등 완전히 0이 아닌 값을 리턴하는데, 이를 dense하다고 한다.
하지만 relu는 0이하의 값은 무조건 0으로 리턴한다.
0이 많다는 것을 sparse하다고 말한다.
relu를 통해 어떤 뉴런의 활성화값이 0이 되는 것이 많아지면,
가중치를 곱하더라도 쭉 0이므로 연산량을 크게 줄일 수도 있다.
- vanishing gradient 문제 해결 -
sigmoid는 gradient가 결국 0으로 수렴하여 사실상 사라져버리는 문제가 일어난다.
실수 범위의 수를 0~1 값으로 매핑하는데, 그럼 아주 넓은 범위의 수들을 무시해버리는 결과가 있을 수 있다.
sigmoid와 달리, relu는 gradient값이 상수로 일정하다.
일정한 gradient값은 빠른 학습을 돕는다.
참고 ▶ 세 번 더 해본 결과다.
결과 1
| 훈련 세트 점수 | 검증 세트 점수 | |
| sigmoid 사용 | 0.878 | 0.871 |
| relu 사용 | 0.904 | 0.877 |
결과 2
| 훈련 세트 점수 | 검증 세트 점수 | |
| sigmoid 사용 | 0.879 | 0.875 |
| relu 사용 | 0.886 | 0.867 |
결과 3
| 훈련 세트 점수 | 검증 세트 점수 | |
| sigmoid 사용 | 0.879 | 0.876 |
| relu 사용 | 0.887 | 0.882 |
# 옵티마이저
적절한 옵티마이저를 선택하여 딥러닝 모델의 성능을 개선할 수 있다.
* 옵티마이저: 경사 하강법 알고리즘
케라스 모델에서는 경사하강법을 선택할 수 있다.
compile()의 매개변수로 넣는다.
기본값 : RMSprop
▶ 옵티마이저 설정 방법
* 혼공머신의 옵티마이저 설명은 맛보기 정도다.
* 더 많은 정보 : 핸즈온 머신러닝 2판
compile()의 매개변수로 설정한다.

keras.optimizers 패키지 아래에 다양한 옵티마이저들이 있다.
많은 옵티마이저들 중에 일단 대표적인 옵티마이저 먼저 시도해볼 수 있다.
다음은 옵티마이저 기능과 연관된 용어이다.
- 모멘텀 최적화(momentum optimization)
SGD 클래스에는 momentum이라는 매개변수가 있다.
0보다 큰 값으로 지정하면, 이전의 그레이디언트를 마치 가속도처럼 사용한다. (기본값 0)
모멘텀 최적화를 2번 반복하여 구현한 것이 네스테로프(nesterov) 모멘텀이다.
* 네스테로프 모멘텀최적화(가속경사) 사용하기
sgd = keras.optimizers.SGD(momentum=0.9, nesterov=True)
- 적응적 학습률(adaptive learning rate)
모델이 최적점에 가까이 갈수록 학습률을 낮추어 안정적인 수렴을 이끈다.
이 적응적 학습률을 사용하는 대표적 옵티마이저 : Adagrad, RMSprop
+ RMSprop와 모멘텀 최적화를 접목한 Adam
learning_rate 기본값 : 0.001
▶ optimizer Adam 사용해보기
아래와 같은 방식으로 optimizer를 지정가능하다.
이런식으로 다양한 optimizer를 테스트해볼 수 있다.

이전 글:
다음 글:
딥러닝 | 과대적합 피하기 | optimizer, dropout (+콜백)
'데이터분석과 머신러닝' 카테고리의 다른 글
| 혼공단 7기 6주차 미션인증 (0) | 2022.02.27 |
|---|---|
| 딥러닝 | 과대적합 피하기 | optimizer, dropout (+콜백) (0) | 2022.02.26 |
| 딥러닝 | 인공 신경망 분류 모델 만들기 (0) | 2022.02.24 |
| [python] k-means clustering visualization module | how to make scatterplot, gif (0) | 2022.02.17 |
| 혼공단 7기 5주차 미션인증 (0) | 2022.02.17 |