학습 글:
2022.02.14 - [데이터분석과 머신러닝] - 머신러닝 | 픽셀 분포의 특징을 뽑아내어 clustering
2022.02.14 - [데이터분석과 머신러닝] - 머신러닝 | k-평균 알고리즘 (KMeans) | 군집 알고리즘
2022.02.17 - [데이터분석과 머신러닝] - 머신러닝 | 주성분분석(PCA)을 이미지 데이터에 적용하여 픽셀 축소하기
4주차 트리알고리즘이 가장 재밌었다고 했는데 바뀌었다.
5주차가 제일 인터레스팅... ㅇㅅㅇ!
역시 시각적으로 들어오는 데이터가 최고다!!
기본 미션:
k-평균 알고리즘 작동 방식 설명하기
# K-평균 알고리즘 (k-means)
군집 알고리즘 중 하나이다.
▶ 알고리즘
ⓐ cluster 개수 k를 미리 지정하면, 무작위로 cluster center를 정해준다.
ⓑ 각 데이터는 가장 가까운 cluster center의 cluster에 속하게 된다.
ⓒ cluster center 재조정 : 각 cluster에 속한 데이터의 평균으로 재조정
ⓓ cluster center에 변화가 없을 때까지 ⓑ~ⓒ 반복
+ 실습 데이터로 k-means 진행 과정을 설명하자면 이렇다.

+ k-means clustering 과정을 누구나 코랩에서 시각적으로 확인할 수 있도록 모듈을 제작했다.
k-means clustering visualization module | how to make scatterplot, gif
위와 같은 gif파일을 만들어주는 메서드도 구현했다.
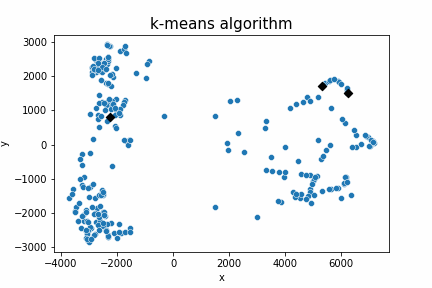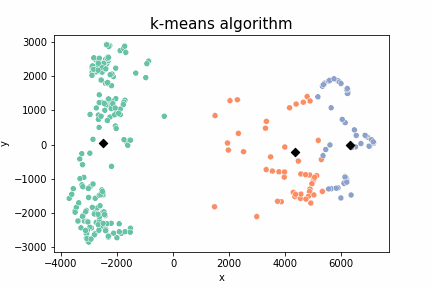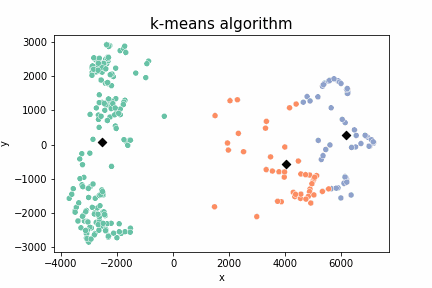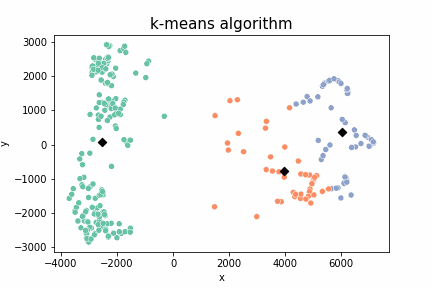
결과물은 이렇다.


랜덤으로 떨어지는 centroid가 부적절했다면 clustering에 실패할 수도 있다.
random centroid가 잘못 떨어져 저렇게 군집이 형성되면 이미지를 의도대로 clustering하지 못한다.
선택 미션:
06-3 확인 문제 풀이과정 정리
2번 문제(PCA후 변환된 데이터셋) 에서 설명된 분산이 가장 큰 주성분은 몇 번째인가요?
답 >> 무조건 ① 첫번째주성분!!!!!
풀이 >> PCA는 주성분을 n개 찾을 때, 원본데이터의 분산을 가장 크게하는 주성분 순서대로 찾는다. 왜냐? 원본데이터의 분포를 가장 잘 설명하는 특성을 만들기 위해서다! 그렇게 찾은 주성분에 원본데이터를 사영하면, 원본데이터를 잘 설명하는 특성 n개를 새로 만들 수 있다.
자세한 내용: 주성분분석(PCA)을 이미지 데이터에 적용하여 픽셀 축소하기
'데이터분석과 머신러닝' 카테고리의 다른 글
| 딥러닝 | 인공 신경망 분류 모델 만들기 (0) | 2022.02.24 |
|---|---|
| [python] k-means clustering visualization module | how to make scatterplot, gif (0) | 2022.02.17 |
| 머신러닝 | 주성분분석(PCA)을 이미지 데이터에 적용하여 픽셀 축소하기 (0) | 2022.02.17 |
| 머신러닝 | k-평균 알고리즘 (KMeans) | 군집 알고리즘 (0) | 2022.02.14 |
| 머신러닝 | 픽셀 분포의 특징을 뽑아내어 clustering (0) | 2022.02.14 |