학습 글:
2022.02.24 - [분류 전체보기] - 딥러닝 | 인공 신경망 분류 모델 만들기
2022.02.25 - [분류 전체보기] - 딥러닝 | 딥러닝 모델 성능 높이기 | layer 추가 & 활성화함수 & 옵티마이저 조정하기
2022.02.26 - [데이터분석과 머신러닝] - 딥러닝 | 과대적합 피하기 | optimizer, dropout (+콜백)
마지막이네요..
더이상 소통하지 않더라도 항상 기억하고 있을게요
힘차게 응원해주셔서 감사했습니다..
넘 따뜻한 방학이었어요..
💝
기본 미션:
확인문제 07-1 풀기
1. 어떤 인공 신경망의 입력 특성이 100개이고 밀집층에 있는 뉴런 개수가 10개일 때 필요한 모델 파라미터의 개수는?
답:
③ 1010개
풀이:
인공 신경망 모델에서의
모델 파라미터: 가중치(w), 절편(b)
모델 파라미터의 개수: 가중치 100*10=1000개, 절편 10개 => 총 1010개
2. 케라스 Dense 클래스로 신경망의 출력층을 만드려 한다. 이 신경망이 이진 분류 모델이라면 activation 매개변수에 어떤 활성화 함수를 지정해야 하는가?
답:
② 'sigmoid'
풀이:
sigmoid는 이진 분류 모델에서 출력층의 출력값을 확률값(0~1)로 바꾸어주는 함수이다. 참고로 양성 클래스에 대한 확률을 반환한다.
(다중 분류 모델일 경우 'softmax'를 이용한다. 각 클래스에 대한 확률을 반환한다.)
3. 케라스 모델에서 손실 함수와 측정 지표 등을 지정하는 메서드는?
답:
④ compile()
풀이:
compile() 메서드의 loss와 metrics에 손실함수, 측정지표를 지정한다.

4. 정수 레이블을 타깃으로 가지는 다중 분류 문제일 때 케라스 모델의 compile() 메서드에 지정할 손실 함수로 적절한 것은?
답:
① 'sparse_categorical_crossentropy'
풀이:
타깃값을 정수 레이블을 타깃으로 가지는 다중 분류 문제
=> 위 손실 함수를 이용하면 정수 레이블을 그대로 이용할 수 있다.
타깃값이 정수 레이블이 아니라 '원-핫 인코딩'된 다중 분류 문제
=> 'categorical_crossentropy'를 사용해야 한다.
선택 미션:
확인문제 07-2 풀기
1. 다음 중 모델의 add() 메서드 사용법이 올바른 것은?
답:
② model.add(keras.layers.Dense(10, activation='relu')
풀이:
① 객체를 생성해 전달해야 하는데 그저 keras.layers.Dense라는 클래스를 전달한다.
③ Dense 생성자 안에 매개변수를 전달해야 하는데 add에다가 전달한 격이라 틀렸다.
④ 1번과 같은 이유로 틀렸다.
2. 크기가 300x300인 입력을 케라스 층으로 펼치려고 한다. 다음 중 어떤 층을 사용해야 할까?
답:
② Flatten
풀이:
keras.layers.Flatten은 여러 차원을 가진 데이터를 1차원 배열로 펼쳐주는 layer다.
그래서 굳이 reshape를 미리 해두지 않아도 된다.
참고로 데이터만 펼쳐줄 뿐 무언가를 학습하는 layer은 아니다.
3. 다음 중에서 이미지 분류를 위한 심층 신경망에 널리 사용되는 케라스의 활성화 함수는?
답:
③ relu
풀이:
relu 함수가 이미지 처리에 효과가 좋다고 한다.
* 참고: relu 이전에는 sigmoid를 주로 썼기에, relu와 sigmoid를 비교하는 것이 옳다고 한다.
- sparse하다는 특징 -
sparse의 반대는 dense하다는 것인데, sigmoid가 그러하다.
sigmoid는 0에 가까운 값이라도 0.0xx 등 완전히 0이 아닌 값을 리턴하는데, 이를 dense하다고 한다.
하지만 relu는 0이하의 값은 무조건 0으로 리턴한다.
0이 많다는 것을 sparse하다고 말한다.
relu를 통해 어떤 뉴런의 활성화값이 0이 되는 것이 많아지면,
가중치를 곱하더라도 쭉 0이므로 연산량을 크게 줄일 수도 있다.
- vanishing gradient 문제 해결 -
sigmoid는 gradient가 결국 0으로 수렴하여 사실상 사라져버리는 문제가 일어난다.
실수 범위의 수를 0~1 값으로 매핑하는데, 그럼 아주 넓은 범위의 수들을 무시해버리는 결과가 있을 수 있다.
sigmoid와 달리, relu는 gradient값이 상수로 일정하다.
일정한 gradient값은 빠른 학습을 돕는다.
4. 다음 중 적응적 학습률을 사용하지 않는 옵티마이저는?
답:
① SGD
풀이:
SGD는 기본 경사 하강법, 모멘텀 알고리즘을 구현할 클래스고, 일정한 학습률을 사용한다.
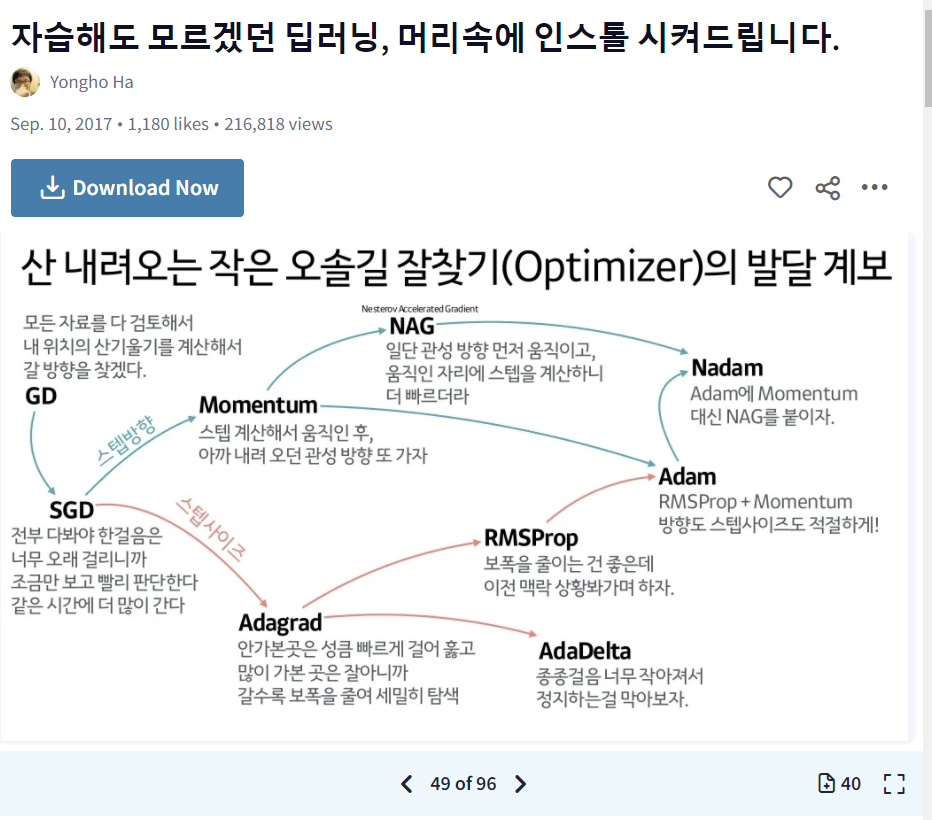
옵티마이저를 비교설명하는 좋은 자료를 찾았다!
Yongho Ha님의 슬라이드.. 너무 좋은 정보들이 많다!!.. 감사합니다
공부할 때 좋을 것 같다. 다들 들어가보세요!! https://www.slideshare.net/yongho/ss-79607172/
'데이터분석과 머신러닝' 카테고리의 다른 글
| integer(0~9) array change process visualization (how to make gif) (0) | 2022.03.01 |
|---|---|
| 딥러닝 | 과대적합 피하기 | optimizer, dropout (+콜백) (0) | 2022.02.26 |
| 딥러닝 | 딥러닝 모델 성능 높이기 | layer 추가 & 활성화함수 & 옵티마이저 조정하기 (0) | 2022.02.25 |
| 딥러닝 | 인공 신경망 분류 모델 만들기 (0) | 2022.02.24 |
| [python] k-means clustering visualization module | how to make scatterplot, gif (0) | 2022.02.17 |