한빛미디어 도서 <혼자 공부하는 머신러닝+딥러닝>의 전개를 따른 내용이다.
챕터 6, 비지도 학습
* 타깃이 없는 데이터를 사용하는 비지도학습과 대표적인 알고리즘을 소개
* 대표적인 군집 알고리즘인 k-평균과 DBSCAN을 배우자
* 대표적인 차원 축소 알고리즘인 주성분 분석 (PCA)를 배우자
그토록 기다리던 비지도학습이다.
개인적으로 비지도학습은 결과를 확인하는 맛이 좀 있는 듯하다.
정답이 없어야 더 도전하는 맛이 있는 느낌이라고 해야하나..!!
[ 포스팅 내용 ]
1. 군집(clustering)
ㅡㅡㅡㅡㅡㅡㅡ( 실습 )ㅡㅡㅡㅡㅡㅡㅡ
2. 이미지 데이터의 구조
3. 픽셀이 이미지 특징을 어떻게 나타낼까
4. 특정 픽셀값 분포를 가진 이미지 골라내기

# 군집(clustering)
비슷한 샘플끼리 그룹으로 모으는 작업이다.
모인 그룹은 cluster라고 한다.
target을 모르는 비지도학습에서, 군집 알고리즘을 통해 비슷한 특징을 가진 샘플끼리 clustering할 수 있다.
.
.
원래 target을 모르는 상태에서 clustering하는 것이 수많은 실제 데이터분석에서 의미가 있다.
하지만 이번 실습에서는 과일종류(target)가 정갈하게 인덱스로 구분된 상태에서,
각각 과일의 픽셀 특징을 뽑아낸 데이터를 사용하여 clustering을 한다.
(즉, 이미 target을 명확히 알고있는 상태에서 각 target의 픽셀특징을 뽑아냈다)
완전히 진흙탕에서 clustering을 하는 것은 아니지만,
"이미지마다 다른 픽셀 분포"를 통해 clustering하는 좋은 실습이다.
(다음 포스팅에서는 target을 모르는 clustering을 진행할 것이다)
(데이터 준비)

# 이미지 데이터의 구조

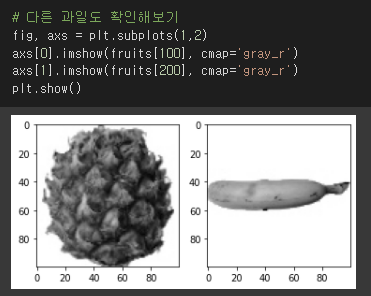
위 픽셀배열이 나타내는 이미지는 무엇인지 imshow()를 통해 그려보자.
이 데이터셋에는 사과, 파인애플, 바나나이미지가 각각 100샘플씩 들어있다.

# 픽셀이 이미지 특징을 어떻게 나타낼까
과일마다 형태와 여백 위치 등이 다르다. 이런 픽셀의 정보를 분석하여 어떤 과일인지 clustering할 수 있을 것이다. 다만, 픽셀을 어떻게 분석해야하지는지가 문제거리다.
두가지를 생각해보자.
▶ 첫번째: 이미지의 픽셀값 평균 차이로 구별
ㄴ문제점: 이미지의 전체픽셀 평균값이 비슷하다는 것 => 서로 같은과일임을 전혀 보장하지 못한다.

▶ 두번째: 동일위치 픽셀 평균값의 차이로 구별
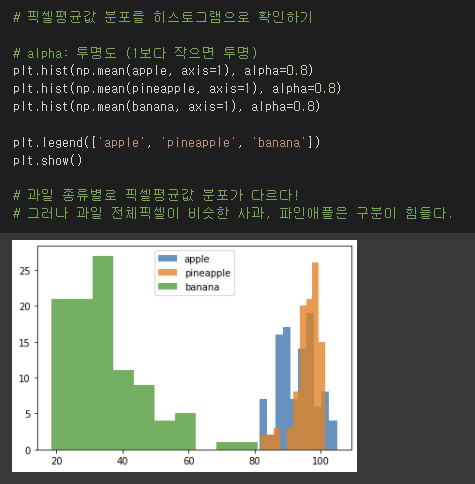
100x100 배열을 1x10000로 늘어놓았을 때, 각 위치마다 픽셀 평균값이 어떻게 분포하는지 확인해보자.
순서대로 사과, 파인애플, 바나나인데, 과일별로 픽셀값 분포 경향이 다르다.
- 사과: 이미지 아래쪽의 픽셀값이 높은 경향이다.
- 파인애플: 전체적으로 픽셀값이 고르다.
- 바나나: 이미지 중앙 픽셀값이 높은 경향이다.


그래서 당연히 두번째 방법으로 생각해야 한다.
위치별로 다른 픽셀값이 즉 이미지의 형태, 명암의 특징을 보여주는 것이기 때문이다.
# 특정 픽셀값 분포를 가진 이미지 골라내기
이전 과정에서, apple_mean에다가 사과 픽셀값 평균치를 100x100 배열로 담았었다.
이 평균이미지와 다른 이미지 300개의 절댓값 오차를 구하자. (abs_diff)
각 이미지의 오차 픽셀 또한 100x100이미지이다. 그 샘플이 가지는 픽셀 오차값 평균을 또 abs_mean에 담자.
그러면 abs_mean에는 샘플갯수 300개 각각에 해당하는 평균오차가 저장되어있다.

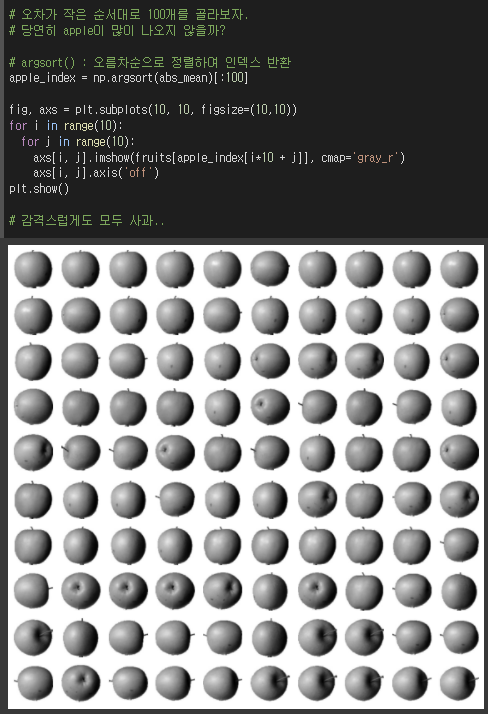
이렇게 apple_mean에 대한 오차가 작은 순서대로 100개를 고르면,
사과에 가까운 것들을 모을 수 있다.
여기서는 운 좋게 모두 사과만 모아졌다.
이번 내용 정리
- 이미지 데이터를 clustering 해보기!
- 이미 가지고있는 이미지데이터의 특징을 직접적으로 뽑아내어 clustering하였다.
다음 글:
머신러닝 | k-평균 알고리즘 (KMeans) | 군집 알고리즘
'데이터분석과 머신러닝' 카테고리의 다른 글
| 머신러닝 | 주성분분석(PCA)을 이미지 데이터에 적용하여 픽셀 축소하기 (0) | 2022.02.17 |
|---|---|
| 머신러닝 | k-평균 알고리즘 (KMeans) | 군집 알고리즘 (0) | 2022.02.14 |
| 혼공단 7기 4주차 미션인증 (0) | 2022.02.13 |
| 머신러닝 | 트리의 앙상블 | sklearn 앙상블 모델 4종류 특징 비교 (0) | 2022.02.13 |
| 머신러닝 | 교차 검증과 그리드 서치 | 최적의 파라미터를 찾아주는 교차검증 방법 (0) | 2022.02.11 |