한빛미디어 도서 <혼자 공부하는 머신러닝+딥러닝>의 전개를 따른 내용이다.
챕터 5, 트리 알고리즘
* 성능이 좋고 이해하기 쉬운 트리 알고리즘 배우기
* 알고리즘 성능을 최대화하기 위한 하이퍼파라미터 튜닝 실습
* 여러 트리를 합쳐 일반화 성능을 높일 수 있는 앙상블 모델 배우기
혼공머신 책에서 하이퍼파라미터라는 용어를 처음 만났을 때,
이걸 최적으로 결정하는 방법은 바로바로 5장에서 배운다고 해서 기다려졌던... 5장..!

# 검증 세트
▶ 테스트 세트로 성능을 조정할 경우의 문제점 :
일반화된 모델을 만들어야 하는데, '테스트 세트'에 적절한 모델이 만들어진다.
▶ 해결 방법 :
훈련세트의 일부를 떼어내 검증세트로 둔다. (훈련세트의 크기는 작아진다)
* 검증세트는 여러개 둘 수 있다 => 교차검증
모델 성능을 개선 기준을 검증세트에 두고 최적화한다.
즉, 검증세트의 score가 좋아지도록 모델의 매개변수를 조정해간다.
그리고 가장 마지막에는 "테스트 세트를 딱 한번만 체크"하여 성능 확인을 끝낸다.


모델의 fit은 현재 검증세트를 제외한 나머지 train set으로 한다.
fit한 뒤에 score를 확인해보았다.
validation set의 score를 확인해보니, train set의 score보다 많이 작다.
∴ 모델의 파라미터를 좀 조정하여 validation set의 score를 높여야겠다.
# 교차검증 해보기
사이킷런의 교차검증 메서드 cross_validate()를 사용해보자.
* 짚고 가기
검증세트1, ..., k 中 검증세트3의 score는
모델을 검증세트 3만을 제외한 train set으로 fit한 모델이 도출한 score다.
최종 검증점수는 각 검증세트에 대한 score의 평균이다.
* k-Fold 교차검증
train set을 k분할로 나누어 검증세트로 둔다.
.
.
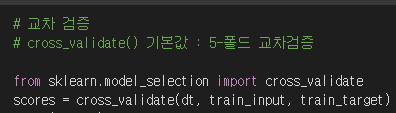
cross_validate()
▶ 기본값 : 5-폴드 교차검증
▶ 폴드를 골고루 나누는 방법? :
검증세트에 타깃 클래스를 골고루 나누기 위해서는 분할기를 사용해야 한다.
기본값으로 StratifiedKFold() 분할기가 지정되어있다.
분할기 StratifiedKFold()에 shuffle=True 매개변수를 지정하면 train set을 골고루 섞은 교차세트를 만들 수 있다.
(회귀 모델의 경우 KFold 분할기를 사용)
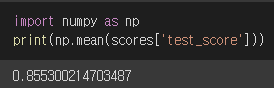
cross_validate()의 리턴값 : 딕셔너리
{'fit_time': array([0.01010561, 0.00961161, 0.01013398, 0.01000714, 0.00965095]),
'score_time': array([0.00130916, 0.00123882, 0.00117517, 0.00128078, 0.00116754]),
'test_score': array([0.86923077, 0.84615385, 0.87680462, 0.84889317, 0.83541867])}
리턴하는 딕셔너리의 세번째 키인 test_score에는 k개의 값이 담겨있다.
이를 평균내서 교차검증의 최종 score를 얻는 원리다.
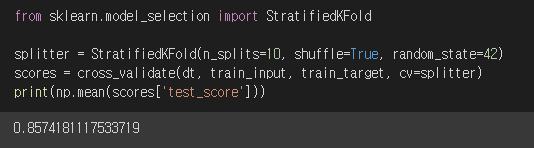
▶ 이때, 분할기 StratifiedKFold()의 shuffle 매개변수를 True로 설정하여 cross_validate()에 cv=분할기 매개변수를 넣으면, train set를 골고루 섞어서 검증세트들을 만들 수 있다.
* 참고
StratifiedKFold 매개변수에서 random_state는 shuffle과 관련된 매개변수다.
그래서 shuffle이 False인데 random_state를 지정하면 이런 오류가 뜬다.
ValueError: Setting a random_state has no effect since shuffle is False. You should leave random_state to its default (None), or set shuffle=True.
+ 추가실습
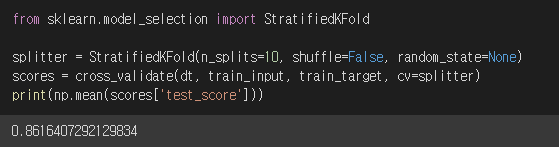
shuffle=False, random_state=None이고 n_splite=5인 상태가,
cross_validate() 메서드의 cv=StratifiedKFold() 기본값이다.
따라서 아래 score 결과는 동일하다
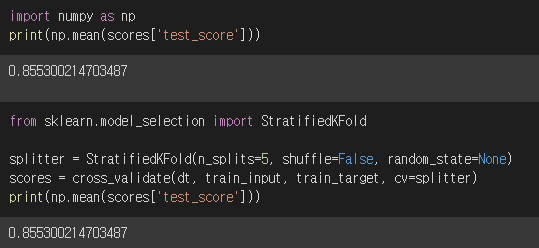
또한 이 모델에서는 n_splites=10으로 지정하여 교차검증의 횟수를 늘리면,
검증세트들의 평균 score가 증가한다.
# 하이퍼파라미터의 최적 조합 찾기 - 랜덤서치
교차검증 score를 높게 하기 위해서 하이퍼파라미터들의 최적 조합을 찾아야 한다.
사이킷런의 GridSearchCV 클래스가 그 최적조합 찾기를 도와준다!
▶ GridSearchCV객체에 '모델', '파라미터 정보', 'CPU코어수'를 넘기면 된다.
* 그리고 '전체 train set'으로 fit한다. (검증세트 나눈 거 말고!)
▶ 그러면 각 파라미터 경우별로 최상의 교차검증 scroe를 확인가능하고,
최적의 파라미터값 또한 알 수 있다.
* 교차검증은 5회가 기본값이다

# 여러 하이퍼파라미터를 전달하는 경우
두가지 교차검증 모델을 사용할 수 있다.
① GridSearchCV 클래스 이용
각 하이퍼파라미터의 수치 범위는 임의의 범위, 임의의 간격으로 지정해주었다.
다만 이렇게 임의로 했을 경우 그 범위나 간격이 올바른지에 대한 판단이 또 필요하다.

② RandomizedSearchCV 이용
이번에는 파라미터의 범위만 지정하고 간격은 지정하지 않는다.
사이파이 라이브러리의 uniform, randint를 사용할 것이다.
RandomizedSearchCV 객체의 파라미터 자리 (param_distributions)에는 딕셔너리가 들어가는데, 딕셔너리의 value에는 확률분포가 들어가야 한다.

[ 과정 ]
① 어떤 확률분포의 지정범위내에서 랜덤으로 하이퍼파라미터 샘플을 뽑는다.
② 총 n번 샘플링하여 n회 교차검증을 시행하도록 객체에 전달하고, fit한다.
* n회 교차검증을 한다는 것의 의미를 오해하지 말자.
k-fold 교차검증의 score는 k개의 검증세트 score를 평균낸 것이다.
이 k-fold 교차검증을 100회 시행하여 100개의 교차검증 score를 얻어서, 가장 좋은 score를 얻는 하이퍼파라미터 값이 무엇인지 알아내는 실습임을 확실히 하자!


결과 확인:
▶ 총 100회의 교차검증 결과 (파라미터값은 랜덤 샘플링됨) ◀
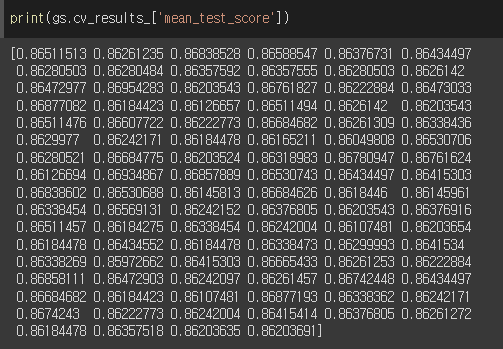
▶ 이 중 가장 큰 값이 최적 모델의 교차검증 결과다! ◀
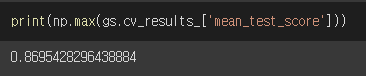
▶ 어떤 파라미터값이 최적이었을까? ◀

위와 같이(접은글) 최적의 모델을 만드는 하이퍼파라미터값을 알아냈다.
그러면 가장 마지막으로,
test set의 score를 확인해보면 된다.

+추가실습
교차검증 cross_validate()에서 cv 매개변수에 분할기 StratifiedKFold()를 전달한 것을 기억해보자.
RandomizedSearchCV 객체에도 기본적으로 StratifiedKFold() 분할기가 지정된다. (아래 문서 참고)
기본적으로 5-fold 교차검증이 사용된다.

① 10-fold로 바꾸어 실습해보았다.
score가 높아졌다. (차이는 근소했음)

② fold는 무조건 같은 수로 분할이 되는 걸까?
최대한 같은 수로 fold를 나누는 것을 확인가능했다.
StratifiedKFold 클래스의 split()메서드에 train_input과 train_target을 매개변수에 넘겨주면, 해당 train set을 또다시 train set과 validation set으로 나눈 index들을 반환해준다.
현재 StratifiedKFold 객체에 n_splits가 10으로 지정되어 있기에, 검증세트는 총 10개 만들 수 있다.

이번 내용 요약
- 하이퍼파라미터 튜닝은 랜덤서치 클래스를 이용하면 좋다!
range로 간격을 딱 정하지 말고, 확률분포 객체를 이용하여 훨씬 넓은 범위의 파라미터 조합을 만들어내서 교차검증할 수 있다.
이전 글:
머신러닝 | 트리 알고리즘 - 결정 트리 (Decision tree model)
다음 글:
머신러닝 | 트리의 앙상블 | sklearn 앙상블 모델 4종류 특징 비교
'데이터분석과 머신러닝' 카테고리의 다른 글
| 혼공단 7기 4주차 미션인증 (0) | 2022.02.13 |
|---|---|
| 머신러닝 | 트리의 앙상블 | sklearn 앙상블 모델 4종류 특징 비교 (0) | 2022.02.13 |
| 머신러닝 | 트리 알고리즘 - 결정 트리 (Decision tree model) (0) | 2022.02.10 |
| 머신러닝 | 확률적 경사 하강법 (0) | 2022.01.30 |
| 혼공단 7기 3주차 미션인증 (0) | 2022.01.30 |