배경지식
[컴퓨터구조] 16비트 컴퓨터 설계하기 - Instruction Cycles
위 글에서 명령어가 수행되는 사이클을 공부했다.
■ 타이밍 T0, T1에서 일어나는 fetch과정,
■ 타이밍 T2에서 일어나는 decode과정,
■ 타이밍 T3에서 명령어의 종류에 따라 수행되거나 수행되지 않는, 유효주소를 AR에 넣는 과정,
■ 그리고 마지막으로 남겨둔, 이번 포스팅에서 확인할, "실행"과정이다!
실행과정은 명령어의 종류에 따라 타이밍 T3 혹은 타이밍 T4에서 진행되고,
또한 명령어의 종류에 따라 실행과정에서의 micro-operation도 다르다.
Execution 과정은 명령어 종류에 따라 다르다!
명령어 종류는 세가지가 있었음을 기억하자.
instruction은 최상위비트 네개가 어떤지에 따라 세가지로 나눌 수 있다고 했다.
(기억 안나면 포스팅 참고: [컴퓨터구조] 16비트 컴퓨터를 설계하자 - Instruction set 정의하기)
■ memory-reference instruction : 최상위비트 하나가 addressing mode고,
그 다음 비트 세개가 operation을 결정하는 명령코드 (피연산자가 필요)
■ register-reference : 최상위비트 네개가 0 1 1 1 이다. (피연산자 필요없음)
■ input-output instruction : 최상위비트 네개가 1 1 1 1 이다. (피연산자 필요없음)
그리고 지난 시간에서 execution단계만 남겨두고 나머지 단계는 모두 보았다.
▷ memory-ref 명령 : T0,T1에서 fetch / T2에서 decode / T3에서 유효주소 담거나 말거나 / T4에서 실행
▷ register-ref 명령 : T0,T1에서 fetch / T2에서 decode / T3에서 실행
▷ I/O 명령 : T0,T1에서 fetch / T2에서 decode / T3에서 실행
그리고 이제 어떤 명령어든 time T4또는 T3에서 execution 단계를 앞두고 있다!
이 execution에서는 어떤 연산이 일어나는지 이번 포스팅에서 지켜보자.
[ 목차 ]
1. Execution of Memory-reference Instruction
2. Execution of Register-reference Instruction
3. Execution of Input-output Instruction
1. Execution of Memory-reference Instruction
아래 테이블은 Memory-ref 명령어의 종류가 잘 정리되어 있다. Memory-ref명령어는 세 비트(14,13,12비트)에 의해 operation이 결정된다고 했었다. decoder에 의해 그 값이 D0~D6에 해당하는 연산이 선택된다.

차근히 생각해보면 모든 명령어가 간단하다.
아래 테이블에서는 time을 표기하여 각 명령어의 과정을 더욱 잘 볼 수 있다.
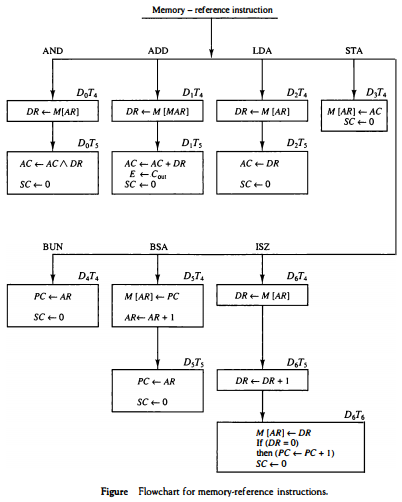
*위 그림 BSA에서 AR<-AR+1이 아니고 PC<-AR+1인 것 같다.
이것들이 memory-ref명령어 사이클의 실행단계에서 거치게 되는 연산 총정리이다.
여기서 BSA instruction이 조금 복잡한데, 이걸 좀 살펴보자.
BSA instruction
◆ BSA는 Branch and Save Return Address다. 서브 프로그램 (subroutine)으로 분기(branch)하고 복귀주소(return address)를 저장하는 명령이다.
◆ 일반적인 컴퓨터들은 return address를 stack에 저장하는데, 우리가 설계할 16비트 컴퓨터는 stack이라는 자료구조가 없다. 그럼 retrun address를 어디에 저장할까? 잠시 아래 그림을 보자!

- (a)를 보자. 20번지에서 BSA 명령이 실행되었다. 이 20번지를 보면 subroutine이 시작되는 번지는 135라고 적혀있다. 그러나 실제로 subroutine의 도입부는 135번지에 있지 않고 136번지에 있다. 이 135번지가 return address를 저장하는 곳이다.
- (a)를 다시 보면 맨 아래에 time T4라고 적혀있다. 얘가 수행하고 있는 명령어가 register-ref명령어니까 time T4에서 execution이 시작되는 것이다. 이번 포스팅은 execution단계의 마이크로연산을 확인하는 포스팅임을 잊지 말자!
◆ time T4 이전 상황 설명
T0에서 AR<-PC를 하고, T1에서 IR<-M[AR]과 PC<-PC+1이 이루어졌었다. 지금 수행하고 있는 명령어에 대한 PC는 20이었고, fetch단계에서 PC<-PC+1가 일어나 PC는 21이 되었다. 그런데 우리는 잠깐ㄹ subroutine으로 갔다가 다시 돌아와야한다. 그래서 '21번지'가 return address이다. 우리는 이 return address값 21을 135번지에 저장해야 한다. 그 과정이, 지금부터 설명할 time T4에서 일어난다.
◆ time T4
M[AR]<-PC
- 메모리의 AR(135)번지에 현재 PC인 21이라는 값을 넣음, 21은 return address임.
PC<-AR+1
- PC를 136으로 증가시킴. subroutine을 수행하러 가기 위해.
여기까지가 time T4에서 일어나는 일이다.
◆ time T5
PC가 136으로 변경된 상태에서 Clock이 뜨면 136번지 명령에 해당하는 subroutine이 실행된다.
subroutine을 쭉 실행하고 막바지에서는 return한다.
(b)에서 subroutine 끝에 있는 [ 1 BUN 135]의 의미를 보자.
< BUN명령어 >
- 다음 수행될 명령어를 지정해주는 명령이다
- '무조건 분기' 또는 '점프'라고 불린다.
BUN명령어는 'PC<-AR, SC<-0'의 연산으로 이루어진다.
AR은 subroutine이 시작되는 번지 바로 이전에 우리가 21라는 return address를 넣어두었던 번지이다. 즉 135라는 값이 들어있다. 그 135번지에 가면 또다시 21이라는 값이 들어있으므로, 다시 21번지로 돌아갈(branch) 수 있다!
그리고 SC를 다시 0으로 바꿔서 타이밍을 초기화한다. (다음 명령을 또 수행해야 하므로)
이렇게 Time T5도 마무리된다.
>> 흐름을 정리하자면 T0,T1에서 fetch, T2에서 decoding, T3에서 effective address 하거나 말거나, T4,T5에서 실행! 우리는 지금 T4,T5의 실행과정을 보았다.
[ 명령어 수행에 대한 이해 plus ]
우리가 지금 설계하고있는 16비트 컴퓨터가 1GHz로 동작한다고 가정하자.
그러면 BSA명령어를 수행하는 데에는 어느 정도의 시간이 걸리는가?
답: 6/10억초
이유:
- BSA명령은 memory-ref명령이다.
- 한 clock에 한 타이밍이 진행되고있고, fetch, decode까지 time T0,T1,T2,T3 이렇게 3클락 소요됨, 그리고 이제 실행단계에서 time T4,T5에 해당하는 두클락이 소요된다.
그래서 총 6클락이 걸렸음.
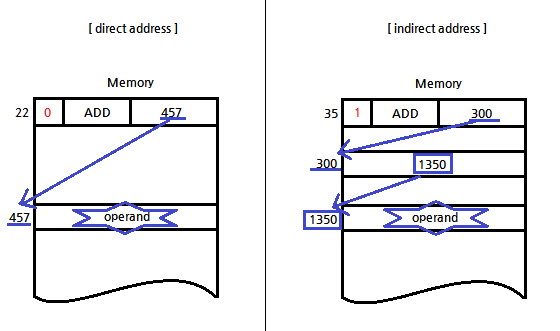
* 생각: 위 그림에서는 BSA명령이 direct모드로 수행되었다. 만약 indirect모드라면 어떻게 될까?
아래 BSA명령어를 보면, addressing mode가 0이므로 direct모드다.
그런데 만약 indirect모드라면 어떨까? 간단하다!
주소부분에 적힌 번지로 가는데, 그 번지에 들어있는 값이 또 번지인 것 뿐이다.
그 번지로 또 가면 된다. 유효한 operand가 나올 때까지!

아래 그림을 참고하면 좋을 듯하다. 이 포스팅에서 설명했던 그림이다.
2. Execution of Register-reference Instruction
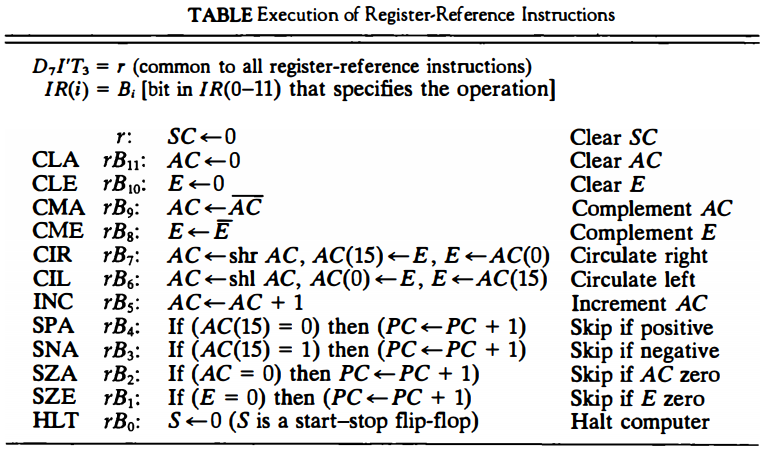
모든 register-reference Instruction은, D7=1이고, I=1이 아니고 (즉 I'), T3=1인 instruction이다.
그래서 register-reference 명령은 D7I'T3으로 표현해보자.
그런데 D7I'T3이라고 표기하기에는 너무 번거로우니까 그냥 저 상황을 r이라고 표현하자.
D7I'T3=r
아래 테이블은 register-ref 명령어에서의 micro-operation들이다.
하위비트 12개, 즉 0~11비트에 의해 register연산이 결정된다.
아래 테이블에 잘 정리되어있다.
[ 명령어 수행에 대한 이해 plus ]
우리가 지금 설계하고있는 16비트 컴퓨터가 1GHz로 동작한다고 가정하자.
그러면 CLA명령어를 수행하는 데에는 어느 정도의 시간이 걸리는가?
답: 4/10억초
이유:
- CLA명령은 register-ref명령이다.
- 한 clock에 한 타이밍이 진행되고있고, 총 4번의 타이밍(T0, T1, T2, T3)에 CLA 명령의 사이클 하나가 돌았기 때문이다. 즉, CLA명령은 4클락만에 수행한다.
3. Execution of Input-output Instruction
다른 포스팅에서 따로 설명하겠다.
너무 길어질 것 같아서!
[컴퓨터구조] 16비트 컴퓨터 설계하기 - I/O instruction의 실행 단계에서 벌어지는 일들
이것도 아주 중요한 내용이니 꼭 보아야 한다.
이번 포스팅에서 본 것은?
■ 실행 단계에서 일어나는 micro연산을 확인했다.
■ 명령어의 종류에 따라 구분해서 실행 단계를 공부했다.
다음 포스팅에서는
명령어의 종류와 상관없이 총체적인 instruction 수행 흐름을 표시해놓은 다음 flowchart를 확인해 볼 것이다.

이 포스팅에서 정리하면 호흡이 너무 길어질 것 같아서,
다음 포스팅으로 끊겠다.
'컴퓨터구조 & OS' 카테고리의 다른 글
| [컴퓨터구조] 16비트 컴퓨터 설계하기 - instruction 실행의 종합적인 흐름 | flowchart (0) | 2021.10.16 |
|---|---|
| [컴퓨터구조] 16비트 컴퓨터 설계하기 - I/O instruction의 실행 단계에서 벌어지는 일들 (0) | 2021.10.16 |
| [컴퓨터구조] 16비트 컴퓨터 설계하기 - Instruction Cycles (2) | 2021.10.15 |
| [컴퓨터구조] 16비트 컴퓨터 설계하기 - Control unit 설계 (0) | 2021.10.14 |
| [컴퓨터구조] 16비트 컴퓨터를 설계하자 - Instruction set 정의하기 (0) | 2021.10.13 |