우리 서비스에서 각종 모델이 돌아가기 때문에 GPU가 있으면 좋다. (아니! 필요한 수준)
조교님께서 연구실 서버 + gpu를 사용할 수 있도록 해주셨다. (감사합니다)
어제는 GPU 세팅을 완료했다.
이제는 우리 VisualRadio 서비스가 GPU를 사용하도록 컨테이너측에서 잡아주는 것만 남았다.
(아직 정리하지 않아서 비공개 글이다!)
2023.09.07 - [미분류2023글] - Linux gpu 세팅[1] | nvidia driver, cuda, cudnn
그나저나 내가 어제 nvidia-docker2를 설치했는데 그럴 필요가 없다고 한다.
그리고 또 도커 이미지를 아예 gpu 전용 이미지로 바꿔야 하는 줄 알았는데 아니더라!
또 밤새는 줄 알았는데... 너무 다행이다.
=> 결론: 밤새고있다ㅋㅋㅋ 그치 이거지
=> 다음날 본질적인 문제점을 찾았다. (밑부분에 정리함)
docker 19 이후에는 nvidia-docker 안 깔고 nvidia-container-runtime만 설치하면 docker에서 gpu 인식이 가능하다고 한다. 나이스!!
현재 서버에는 이미 이렇게 준비 완료!
■ Docker version 24.0.6, build ed223bc
■ NVIDIA-SMI 470.199.02 / Driver Version: 470.199.02
이 희소식은 이 글을 통해 알았다.
정말 감사합니다.
https://data-scient2st.tistory.com/46
[docker] docker GPU 설정
예전 글들을 보면 docker container에서 gpu 를 사용하기 위해서는 nvidia-docker를 새로 설치해야된다고 합니다. 하지만, docker 19.*.* 이후부터는 docker 자체에서도 gpu를 지원하게 되었습니다. 따라서 현 시
data-scient2st.tistory.com
이때 docker에서 gpu를 잡기 위해 필요한 것은 nvidia-container-runtime이다.
일단 우리 서버에는 깔려있다.
아마 nvidia-docker2를 설치하면서 같이 설치된 게 아닐까? 싶다.
- nvidia-container-runtime 설치 여부 확인하기:
which nvidia-container-runtime-hook
.
.
[참고]
* 설치되어있지 않다면 설치해야 한다.
apt-get install nvidia-container-runtime
* 설치 후 docker restart가 필요하다.
sudo systemctl restart docker
* 이제 gpu를 잘 잡는지 확인하기 위해, 컨테이너 띄울 때 --gpus 옵션 줘서 띄워보면 된다. 그 컨테이너에서 nvidia-smi를 통해 gpu가 인식되는지 확인하면 된다.
docker run -it --rm --gpus all ubuntu nvidia-smi
GPU 옵션 줘서 컨테이너 띄우기 (⭕잘했다)
여기서 보시면 된다!
https://www.oofbird.me/68
[docker-compose] NVIDIA GPU 사용하기
docker-compose 로 Docker 서비스를 구성할 때 NVIDIA GPU를 접근하는 방법에 대해 설명합니다. 사전필요사항 아래 내용을 진행하기 위해서는 다음사항이 준비되어야합니다. NVIDIA GPU Driver 설치 NVIDIA-CONTAI
www.oofbird.me
우리 팀은 docker-compose를 사용하여 한번에 띄우고 있다.
그래서 docker-compose 옵션에 gpu 옵션을 추가할 것이다.
앞서 nvidia driver도 잘 설치됐고, 앞서 nvidia-container-runtime이 설치된 것도 확인했다.
그럼 옵션 주고 빨리 띄워보자!
이 글에 안내된 대로, 우리 docker-compose는 v1.28.0 이상이다.
■ Docker Compose version v2.21.0
그래서 docker-compose.yaml에 device옵션을 주는 것만으로 gpu 옵션 지정이 가능하다.
그래서 간단히 docker-compose.yaml에 다음과 같이 devices를 지정했다. (맨 아래 deploy: 하위를 보면 된다.)
띄워봤더니, 컨테이너 안에서 nvidia-smi로 GPU가 잡힌 것을 확인할 수 있었다.
docker-compose 너무 편안하네!
visual-radio:
container_name: visual-radio
build: ./VisualRadio
# image: yenyeny1/visual-radio:0.1
restart: always
ports:
- 5001:5001
networks:
- db-net
volumes:
- .:/app
depends_on:
- mysql
environment:
- TZ=Asia/Seoul
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu, utility]
GPU 사용하는 모습 확인해보기 (⭕잘함)
서버가 돌아갈 때 GPU를 사용하는지 확인해보자
아래 명령어를 통해 1초마다 확인 가능하다.
nvidia-smi -l 1어? 근데 아무것도 GPU를 못 쓰네?
다시 체크 간다.
■ Tensorflow 버전을 확인하세요 (⭕잘함)
돌려보니까 아무 것도 gpu에서 실행이 안 되더라. tensorflow
소스코드에 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") 라는 코드가 있어서 cuda를 왜 사용 못하는지 검색해봤다. 그러다가 호환성을 다시 한번 검토해보았다.
현재 사용중인 tensorflow는 2.13.0인데, cuda와 cudnn 버전과 호환되지 않는 상태였다.
문제를 바로 발견해서 압도적 기쁨!!
이 중에서 하나로 변경해야 한다.

현재 서버의 cudnn, cuda 버전과 호환되는 버전인 tensorflow 2.5.0으로 설치해보기로 했다.
기존에 tensorflow 2.13.0을 사용하던 중이라, 다른 라이브러리와 호환이 안 될까봐 무서웠지만, 그냥 테스트해봐도 상관 없어서 일단 진행해봤다. 다행히 충돌이 안 나더라!
tensorflow 2.5.0으로 확정하자.
■ 버전 호환 맞춘뒤 CUDA 사용 확인해보기 (⭕잘함)
tensorflow도 제대로 깔았으니!
model이 predict할 때 gpu를 돌리는지 확인해보았다.
안된다! (아 제발요!)
그래도 필요했던 과정이라고 생각한다.
■ 안되는 이유 두가지 발견
반복해서 고민하고 시도한 끝에 문제를 또 발견했다.
- cudnn설치가 제대로 안됨 (❌잘못함!!! 호스트 cudnn을 체크해버림. 컨테이너에서 체크해야 했는데)
---> 설치파일을 올바른 경로로 이동하지 않음
- 컨테이너 내부에서 cuda가 잡히는게 중요한데 시스템에서만 확인함 (⭕잘 체크함)
---> cuda 설치 위치의 혼동
# cudnn 올바르게 세팅 (올바르지 않았다. 컨테이너가 아닌 호스트에서 세팅해버렸다.)
압축풀기한 설치파일을 올바른 경로로 복사하는 과정을 누락했다. (꼼꼼함이 부족한 나였죠)
sudo cp lib64/* /usr/local/cuda-11.2/lib64/
sudo cp include/* /usr/local/cuda-11.2/include/
sudo chmod a+r /usr/local/cuda-11.2/lib64/libcudnn*
sudo chmod a+r /usr/local/cuda-11.2/include/cudnn.h찐으로 설치확인!
설치 확인
cat /usr/local/cuda-11.2/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
이런식으로 뜬다
#define CUDNN_MAJOR 8
#define CUDNN_MINOR 1
#define CUDNN_PATCHLEVEL 1
#define CUDNN_VERSION (CUDNN_MAJOR * 1000 + CUDNN_MINOR * 100 + CUDNN_PATCHLEVEL)
#endif /* CUDNN_VERSION_H */# 컨테이너에 cuda 설치 재진행
cuda설치.. 이걸 몇번째 하는 건지 문득 궁금해진다.
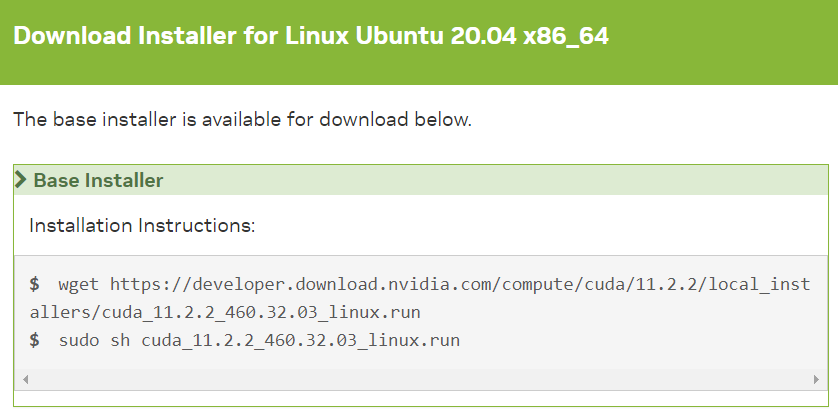
driver는 설치되어 있으니까 체크 해제 후 진행
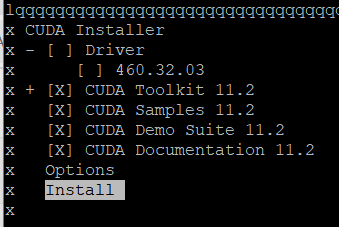
CUDA를 잘 설치하고, 컨테이너 내부에서 nvcc -V를 확인 완료했다.
그런데 또 다른 문제점 발견!
nvidia-smi를 했을 때, 시스템과 호환되는 CUDA Version이 같이 떠야 하는데
N/A로 표시되는 문제를 이제서야 발견했다.
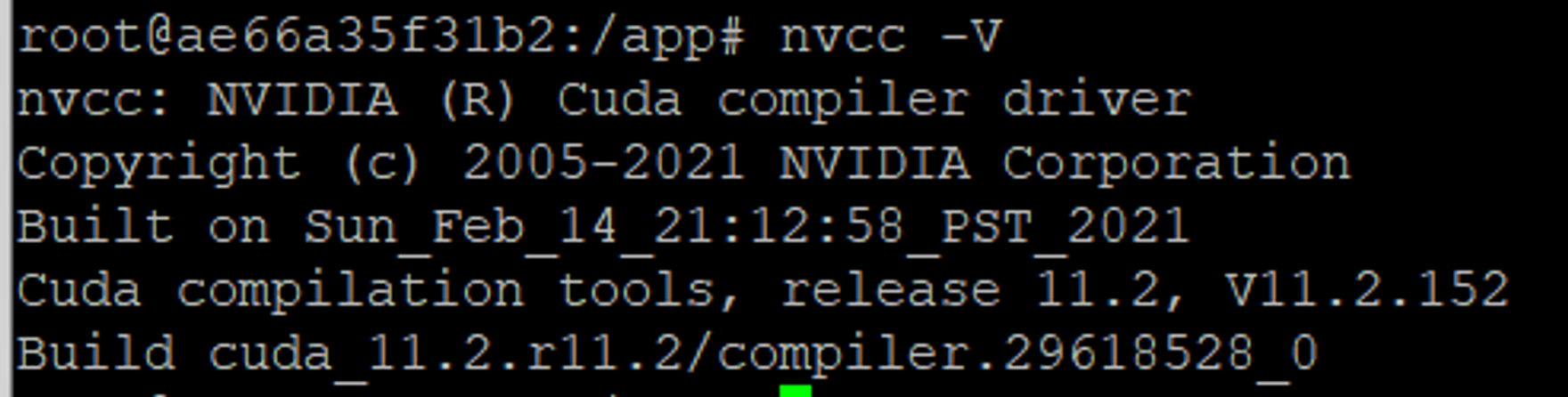
도커 이미지 변경 안하고 컨테이너 띄울 때 gpu 옵션 주는 것만으로 해결할 수 있을 줄 알았는데 N/A가 떠버리다니!
우리 팀 서비스의 운명은?
반드시 살리고만다..
■ 컨테이너에서 CUDA Version N/A문제 해결하기 (⭕잘함)
컨테이너에서 CUDA Version을 추천 못 해준다는 것은 무엇 때문일까?
Ubuntu 20.04 환경인것도 동일하고, nvidia driver도 호스트와 동일한 버전이라 문제가 없어야 한다고 생각한다.
그래서 원인을 잘 모르겠다.
오랜 시간동안 다시 컨테이너에 CUDA도 재설치해보고, cudnn 설정도 다시 해보고, nvidia driver도 계속 재설치! 재설치! 중간에 충돌도 나면 다시 싹 지우고 재설치 재설치!! 아우! ㅎㅎ
.
.
천천히 생각해보았다. 근데 N/A를 본 적이 없었는데?
이전에 캡쳐해둔 걸 확인해봐야겠다.
여기서 확실한 것은, 컨테이너에서 CUDA Version이 정상적으로 뜬 적이 있었다는 것이다.
sudo docker run --rm --gpus all nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04 nvidia-smi
이 컨테이너를 띄워보면, CUDA Version이 11.4로 잘 추천되었다.
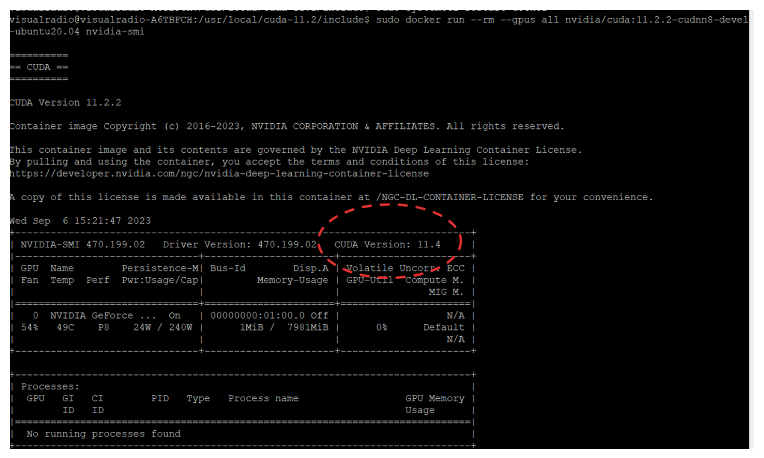
그래서 이미지를 이것저것 바꿔봤다.
CUDA Version이 정상적으로 떴던 것들 말이다.
- nvidia/cuda:11.2.2-cudnn8-devel-ubuntu20.04
- ubuntu:20.04
그런데 둘 다 안되더라. 여전히 N/A...
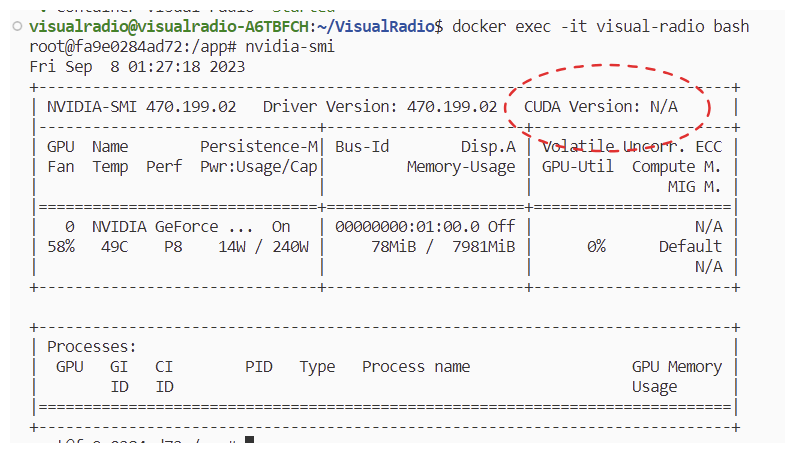
이미지는 똑같은데 왜
직접 run으로 --gpus 옵션을 준 것은 정상적으로 CUDA Version이 추천되고,
내가 docker-compose로 옵션을 부여한 우리팀 컨테이너는 CUDA Version이 N/A가 될까?
어! 혹시 docker-compose.yaml에 옵션을 잘못 줬나?
그래서 다시 찾아보니까
어떤 분은 gpu 옵션에다가 [gpu, utility]를 주는데, 어떤 분은 [gpu]만 줬다.
그래서 나도 기존에 쓰던 이미지에 gpu로만 주고 시도해봤다.
바로 뜨네?
(허무하지만 잘됐다! 아냐 허무한 건 아냐 근데 좀 힘들었어!)
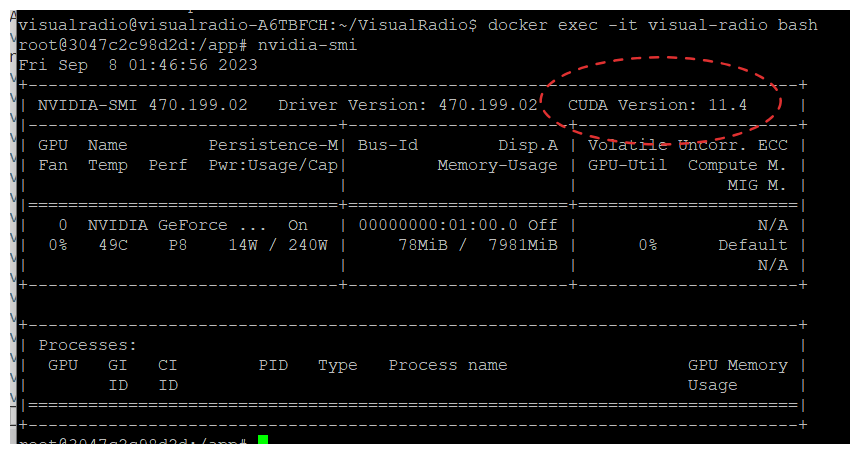
여전히 TensorRT는 안 잡히지만 무시해도 GPU사용에 지장 없다는 얘기가 있으니 무시한다고 치자.
일단 cuda는 잡힌다.
그런데 중요한건 아직 cnn 모델 돌릴 때 GPU를 사용한다고 찍히지 않는다.
왜 그런 걸까?
(지금 딱 8시간동안 의자에서 못 일어났다. 이제 자러 갈래.)
내일 해결하자.
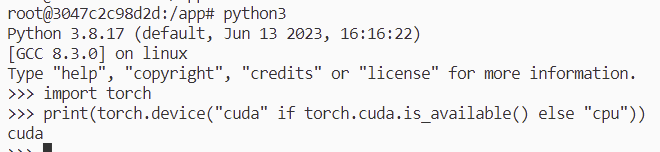
■ 문제점:
cudnn 세팅을 컨테이너에서 안 했다... GPU 돌아가는 환경이 호스트인지 컨테이너인지 명확하게 안 구분지었던 나의 문제였다. cuda와 cudnn의 역할을 뚜렷하게 인지하지 못한 채로, 다들 호스트에 설치하고 도커 띄우는 것 같길래 그냥 그러면 되는 줄 알았다.
아오... 그게 아니지...! 왜 너 넘겨짚었어? 당연히 cuda를 돌릴 환경에서 cuda세팅을 해야 하는 거잖아. 나 호스트에서 돌릴 거 아니잖아. 컨테이너에 cuda세팅해야 한 거잖아..
이런.. 항상 짚어가면서 생각하는 태도를 유지하자..
▼ 결론: cuda설치와 cudnn설치를 컨테이너에 다시 진행하자.
■ 명확하게: CUDA와 cudnn을 컨테이너에 세팅해야 한다
다시 짚어보자.
목적: 컨테이너에서 GPU를 사용하도록 한다.
현재 문제점: 컨테이너 내부에서 cuda는 잡히지만 GPU 사용을 못한다.
의심: cudnn 세팅 미완료가 의심된다. 이 서버의 TensorRT 문제가 cudnn 세팅 후 사라졌던 적이 있었다. 그렇게 사라지게 할 수 있는 것인데 뜨는 상태인 것으로 보아서는 cudnn 세팅이 비정상이기 때문일 것이다.
시도: cuda설치와 cudnn설치를 진행했다.
왜?: 호스트에 nvidia driver를 설치한 이유는 호스트 시스템이 gpu를 잡게 하기 위해서다. 호스트에 cuda와 cudnn을 설치한 이유는 호스트에서 돌리는 모델이 cuda를 사용할 수 있도록 하기 위해서다.
내가 간과한 것은 "컨테이너 내에서 돌려야 한다는 것"이다. 즉 호스트가 아니라 컨테이너 환경 구축이 필요한 것이다.
nvidia driver는 당연히 호스트 시스템 드라이버에 설치해야 하는 것이고
cuda와 cudnn은 컨테이너에서 돌려야 하니까 컨테이너에 설치해야 하는 것이다.
내가 살짝 무지성으로 진행했던 것을 반성한다.
이렇게 천천히 생각해보면 풀릴 문제를 명확히 정의하지 않은 채
"호스트에 cuda랑 cudnn 설치했다~"
"컨테이너에서 nvidia-smi 잘 잡히는 거 확인했고~"
"어? 근데 CUDA가 available인데 왜 사용을 못하고 있지???"
이렇게 꼼꼼하지 못하게 끌고갔다.
이제는 말할 수 있는것..
"nvidia driver는 그냥 당연히 호스트에 설치하면 끝인 거고"
"당연히 컨테이너 내에 cuda, cudnn 환경을 구축해야지! 호스트에서 모델 돌릴 거 아니잖아"
■ 역시 깨끗하게 생각해야 뭐든 잘 돼!!
* TensorRT 문제는 사라지지 않았지만 GPU 돌리는데 문제 없다는 말이 있으므로 pass!
GPU로 spleeter 모델이 돌아간다!!
정확히는, GPU로 돌리려고 한다. 오류가 나지만!
아무튼 이제 오류만 잡으면 된다! (으아아 화이팅!!)
다행!
'컴퓨터구조 & OS' 카테고리의 다른 글
| [python] gpu(cuda) 프로세스 정리하기 (0) | 2023.09.12 |
|---|---|
| [Nvidia][Docker] 컨테이너에서 GPU 돌리기! (0) | 2023.09.09 |
| [WSL와 VM의 차이점] 하이퍼바이저를 이해하며.. (2) | 2023.09.07 |
| 도커는 호스트 시스템에 영향을 받는다 2편 - tensorflow 관련 ImportError (1) | 2023.07.05 |
| 도커는 호스트 시스템에 영향을 받는다 1편 - platform 속성? amd64와 arm64/v8 (CPU 아키텍처) (2) | 2023.07.05 |