스펙트로그램 정규화 필요성
음성 구간(30초)이 "노래구간"인지 "광고구간"인지 분류하는 이진분류 모델을 만들고 있습니다.
지금까지는 정규화하지 않은 데이터로 만든 모델을 만들어서인지, 색다른 데이터에 해보니까 분류를 꽤 못했습니다.
당연스럽게도 적절한 정규화 방법을 선택했어야 합니다.
저는 음성 데이터로 STFT, MFCC, Mel spectrogram의 세가지 스펙트로그램 데이터를 사용하고 있습니다.
각각의 스펙트로그램은 어떤 방식으로 정규화되어야 할까요?
저는 이렇게 정규화했습니다.
* 먼저, 이상치는 제거하지 않았습니다.
분류기로 선택한 모델이 음성분류에 특화되었다고 해서 어차피 이상치에 덜 민감하지 않을까 싶어서입니다.
그리고 이상치에 대한 세밀한 분석은 하지 않았기 때문에, 그냥 두고 진행했습니다.
나중에 이상치 분석의 필요성이 느껴지면 그때 하겠다는 생각입니다.
✨ STFT: np.log(1 + 1000 * np.abs(stft))
✨ MFCC: min-max
✨ Mel spectrogram: dB로 변환
정규화 방법을 선택하면서, 로그스케일 정규화와 데시벨에 대해 알고 갑시다.
로그스케일 정규화
각 값에 로그를 취하여 스케일을 조정하는 방법입니다.
스펙트로그램과 같은 주파수 영역 데이터에서 사용할 수 있다고 합니다.
로그를 취함으로써 큰 값과 작은 값 사이의 차이를 줄이고, 주파수 데이터의 변화를 더 잘 관찰할 수 있게 됩니다.
데시벨(dB) 스케일 변환
인간의 귀는 로그적으로 소리를 감지합니다.
데시벨은 소리의 측정값(주파수)을 로그스케일로 변환하여 10배한 것입니다.
신호는, 실제 측정값인 주파수(소리, 전압, 전류)에 비례하지 않고 데시벨에 정량적으로 비례하는 특성을 가진다고 합니다. 그래서 회로를 다룰 때도 데시벨을 사용하는 것이라고 합니다.
dB 단위는 왜 쓸까? http://sbtech.kr/bbs/board.php?bo_table=sbtech_techdata&wr_id=4
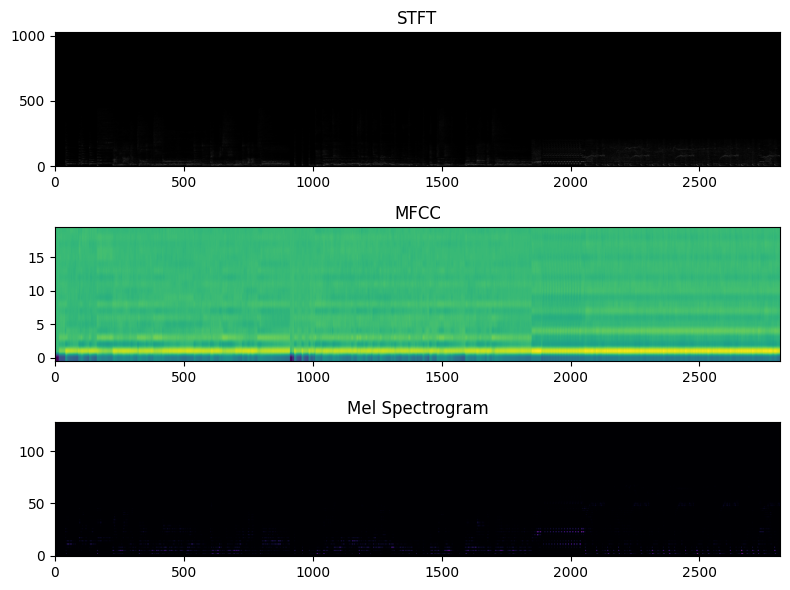
정규화 전후 스펙트로그램 비교하기 (x, y축은 생략)
STFT, MFCC, Mel spectrogram에 대하여
정규화 전후 스펙트로그램 이미지를 비교해보겠습니다.
정규화 안한 것, 모두 min-max정규화한 것, 각각 다르게 정규화해본 것 입니다.
1. 정규화 안함

stft = np.abs(librosa.stft(audio))
mfcc = librosa.feature.mfcc(y=audio, sr=sr, n_mfcc=20
mel_spectrogram = librosa.feature.melspectrogram(y=audio, sr=sr, n_fft=512)
2. 모두 min-max 정규화
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
stft = np.abs(librosa.stft(audio))
stft = scaler.fit_transform(stft)
mfcc = librosa.feature.mfcc(y=audio, sr=sr, n_mfcc=20)
mfcc = scaler.fit_transform(mfcc)
mel_spectrogram = librosa.feature.melspectrogram(y=audio, sr=sr, n_fft=512)
mel_spectrogram = scaler.fit_transform(mel_spectrogram)
3. STFT는 로그, MFCC는 min-max, Mel spectrogram은 데시벨(로그)
# stft는 로그 변환 정규화
stft = np.abs(librosa.stft(audio))
stft = np.log(1 + 1000 * np.abs(stft))
# mfcc는 min-max 정규화
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
mfcc = librosa.feature.mfcc(y=audio, sr=sr, n_mfcc=20)
mfcc = scaler.fit_transform(mfcc)
# mel은 데시벨로 변환(로그)
mel_spectrogram = librosa.feature.melspectrogram(y=audio, sr=sr, n_fft=512)
mel_spectrogram = librosa.power_to_db(mel_spectrogram, ref=np.max)
* 참고:
코드에서 설정한 n_fft=512와 n_mfcc=20는 이런 근거로 선택했습니다.
- n_mfcc: 일반적(음성처리)으로 20 사용 http://keunwoochoi.blogspot.com/2016/01/
- n_ftt: # librosa 공홈에서, 음성처리의 경우 n_fft=512권장(한다고 함)
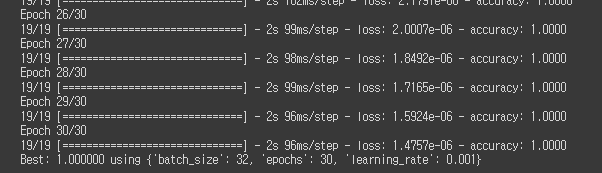
모델의 정확도가 상승 & loss의 대폭 감소
엄밀한 성능측정 비교는 하지 않았지만 대략적으로 적어두겠습니다.
- loss가 매우 눈에띄게 감소
- accuracy 1.0이 당연해진 느낌 (그치만 train_data에 대한 accuracy긴 합니다)
실제 데이터에 적용해보고 오겠습니다.
오.. 마음에 들어..
테스트는 더 해봐야겠습니다.
스펙트로그램 정규화의 더 좋은 방법이 있다면 댓글 부탁드립니다.
참조
http://sbtech.kr/bbs/board.php?bo_table=sbtech_techdata&wr_id=4
https://sswwd.tistory.com/4
'미분류글' 카테고리의 다른 글
| [github] 원격지 접근시 ssh 공개키 인증 방식 (+개인키는 windows와 wsl에서 별도로 둬야 한다) (2) | 2023.09.01 |
|---|---|
| gensim 설치 혹은 import 오류 해결기 (잘 체크하기!) (1) | 2023.08.08 |
| [git] 특정 파일만 이전 커밋으로 돌리기 (checkout은 branch 변경만 하는 게 아니구나!) (0) | 2023.07.28 |
| [vscode] 클라우드 서버에 ssh 접속 후 container 접속하기 (0) | 2023.05.11 |
| 데이터통신 - Multiplexing 기술 - FDM (Frequency-Division) (0) | 2023.04.29 |