
한빛미디어 도서 <혼자 공부하는 머신러닝+딥러닝>의 전개를 따른 내용이다.
이번에 다룰 내용은 "회귀 이해하기"이다.
특히 지금 실습하며 배울 것은, k-최근접 이웃 알고리즘을 사용해서 농어의 무게를 예측해보는 것이다.
농어의 길이 data를 통해 농어의 '무게'를 예측해볼 것이다.
튜터링 할때 이 회귀 파트를 아이들에게 열심히 설명해주었던 생각이 난다.
다시 굳은 기억으로 남을 수 있게 정리 꼬~~~

챕터 3, 회귀 알고리즘과 모델 규제 | k-최근접 이웃 회귀
* 지도 학습 알고리즘의 한 종류인 회귀 알고리즘 배우기
* 다양한 선형 회귀 알고리즘의 장단점 이해하기
지도 학습 알고리즘은 크게 '분류'와 '회귀'로 나눈다.
- 분류 : 이 클래스가 A클래스냐 B클래스냐
- 회귀 : 두 변수 사이의 상관관계를 분석하는 방법
오늘은 k-최근접 이웃 알고리즘을 통해 회귀를 이해해보자.
그런데 k-최근접 이웃 알고리즘은 '클래스 분류'에 사용했었다.
그런데 어떻게 수치를 예측하는 '회귀'에도 적용될 수 있을까?
k-최근접 이웃 알고리즘이
- 분류에 적용되었을 때 :
샘플의 가장 근처에 있는 데이터를 살펴보고, 가장 많은 클래스를 샘플의 클래스로 예측해준다.
k-최근접 이웃 분류 알고리즘 구현 클래스는 KNeighborsClassfier이다.
- 회귀에 적용되었을 때 :
샘플의 가장 근처에 있는 수치를 살펴보고, 그것들의 평균값을 샘플 특성 수치로 예측해준다.
k-최근접 이웃 회귀 알고리즘 구현 클래스는 KNeighborsRegressor이다.
( 샘플의 이웃 데이터를 살펴보아 예측한다는 알고리즘은 동일하다.
'최근접 이웃'이라는 이름 자체에서도 쉽게 느낄 수 있다. )
# 데이터 준비하기
당연히 지도학습에는 train set과 test set이 필요하므로 후다닥 준비해보자.
+ 이제부터 데이터 준비하기는 접은글에 작성하겠다! 핵심 주제가 아니므로..
- data의 산점도 확인
- 지도학습을 위한 train/test set 나누기
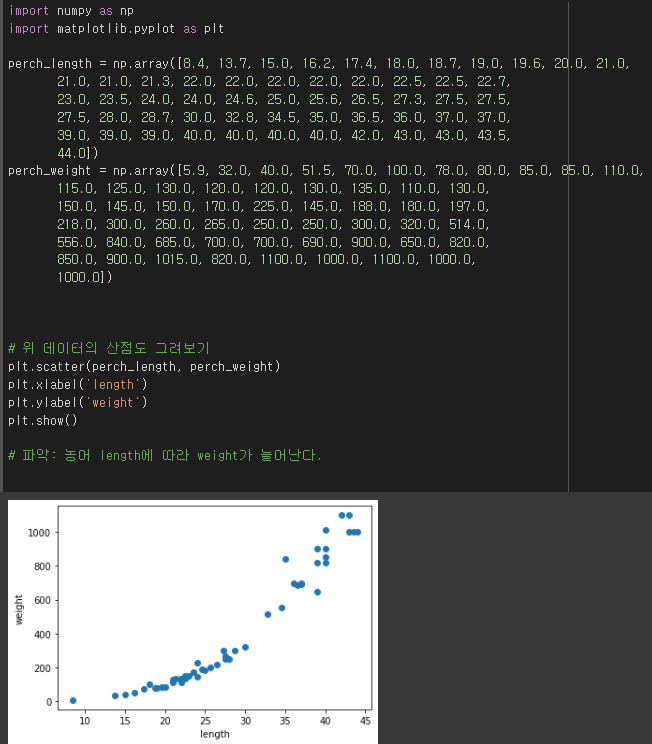
데이터 준비 1. data의 산점도 확인
간단히 보고 넘어가자.
데이터 준비 2. train/test set 나누기
이전과 같은 과정으로 train/test set을 나눈다.
sklearn 패키지의 train_test_split을 이용한다.
다만 1차원배열을 split했기에 1차원배열로 리턴한다.
그러나 사이킷런에 이용하려면 2차원 배열이어야 한다.
2차원배열로 형태를 바꿔주기 위해 넘파이의 reshape()를 이용했다.
+ 두 가지 방법으로 모두 사용 가능하다.
any_array.reshape(2,2)
np.reshape(any_array, (2,2))
train/test set 나누기도 끝!
.
.
위와 같이 산점도를 통해 데이터를 파악해보았고,
train/test set도 나누기 완료!
그리고 sklearn에 이용하기 위해 2차원 배열로 만들기도 완료!
train/test set도 만들었으니,
이를 이용해서 이제 k-최근접이웃 알고리즘을 훈련시킬 차례다.
k-최근접이웃 회귀 알고리즘을 구현한 클래스인 KNeighborsRegressor()의 인스턴스를 생성하고,
이번에도 역시 fit()으로 훈련시키고 score()로 성능을 확인하자.
아래와 같이, 약 0.99의 수치가 나왔다.
분류모델에서는 이 평가수치를 '정확도'라고 했지만, 회귀모델에서는 A냐 B냐를 맞추는 것이 아니라 수치를 예측하는 것이기 때문에 정확도라는 표현은 부정확하다. 대신 "결정계수(R^2)"라고 한다.

# 결정계수(R-squared)
SST = Total Sum of Squares(총제곱합)
SSR = Residual Sum of Squares(회귀제곱합)
R^2 = 1 - (SSR/SST)
그래서 예측치가 target이 아니라 target의 평균에 가까울수록 R^2는 작아진다.
이렇게 회귀모델에서 결정계수 R^2를 통해 얼마나 잘 예측하였는지를 평가할 수 있다.
++ 참고
얼마나 잘 예측하였을지를 다른 방법으로도 볼 수 있다.
test 데이터들에 대한 예측값과 test target 데이터들간의 평균 오차가 얼마나 되는지를 정량적으로 직접 확인하는 것이다.
아래와 같은 과정으로, 물고기 weight를 예측한 것이 실제 target과 평균적으로 19g차이가 난다는 사실을 확인 가능하다. 실제 몇그램이 차이가 나는지 궁금하면 이렇게 해보는 것도 좋을 듯하다.

# 과대적합, 과소적합
머신러닝 지도학습에서는 모델을 훈련시키고, 평가한다.
훈련시킬 때는 train set으로 fit()하고, 평가할 때는 test set으로 score()를 확인한다.
그런데, 훈련이 올바르게 된 것인지도 판단해야 한다.
훈련은 train set으로 하므로, "train set에 과대/과소적합 되었는지"를 보면 된다.
- 만약 train set에 과대적합 되었다면 test set에 모델이 잘 먹히지 않아 성능이 좋지 않을 것이고,
- 만약 train set에 과소적합 되었다면 test set보다 train data의 score() 값이 작아버릴 수 있다.
(train set으로 훈련했으므로, 당연히 train set으로 test한 score()값이 더 높아야 한다.)
혹은 train set의 score() 값 자체가 낮게 나올 수 있다.
그래서 우리는 train set으로 모델을 테스트한 결과도 확인할 것이다.
그리고나서 test set으로 모델을 테스트한 결과와 비교해보자.
과소 or 과대적합이 일어났는지 확인하자

이상한 점 발견!
당연히 train set의 평가한 점수가 더 높아야 하는데, test set의 평가점수가 더 높다.
이게바로 과소적합의 한 사례다.
>> 과소적합이 일어나는 원인
- train set에 적절히 훈련되지 않은 경우 (일반적인 원인)
모델이 너무 단순해서 훈련이 잘 먹히지 않은 경우이다. 모델을 좀 더 복잡하게 만들면 해결이 된다.
- train set, test set의 크기가 너무 작은 경우
모델을 어떻게 복잡하게 만들까?
우리는 k-최근접이웃 알고리즘을 이용하여 회귀모델을 만들었다.
이 k-최근접이웃 알고리즘은 최근접 이웃 k개를 파악하여 예측결과를 내놓는데, 이웃 몇개를 사용할지는 선택가능하다. (default: 5개)
고려할 이웃 수가 많으면 아주 슉슉 판단할 수 있겠지만,
고려할 이웃 수가 적으면 좀 더 민감하고 복잡한 모델이 된다. 즉 적은 정보로 패턴을 파악해야 한다는 말이다. 그래서 train set에서의 적은 이웃 기준으로 훈련하게 되므로 test set에서의 score()보다 train set에서의 score()를 끌어올릴 수 있다. 이렇게 과소적합을 피할 수 있다.
그럼 고려할 이웃 수를 3개로 줄여서 다시 회귀모델을 훈련시켜보자!

이렇게 모델을 좀 더 복잡하게 하였더니 train set에 대해 R^2가 감소했다.
그리고 이제는 test set의 R^2가 train setdml R^2보다 작아졌으므로, 과소적합을 피했다!
게다가 두 R^2 차이가 작아서 참 괜찮다. 오케이 >ㅅ<
(최적의 이웃 개수를 찾는 방법이 5장에서 나온다고 하니 기대한다.)
# 이번 내용 정리
- 회귀 알고리즘 이해하기
- k-최근접이웃 회귀 모델 만들어보기
- 과대적합, 과소적합 이해하기
- 과소적합을 피하기 위해 '모델의 복잡도를 높이는' 실습 해보기
: k-최근접이웃 회귀 모델에서 이웃 수를 줄여 train set으로 훈련하면, train_set의 score()값을 train_set의 score()값보다 높게 할 수 있다. 좀 더 train_set에 유리하도록 알고리즘을 수정하면 과소적합을 피할 수 있는 느낌으로 알아두면 될 듯하다.
이전 글 :
머신러닝 | 데이터 전처리 | 스케일 조정, 표준화하여 전처리 | 표준점수로 변환
다음 글 :
'데이터분석과 머신러닝' 카테고리의 다른 글
| 혼공단 7기 2주차 미션인증 (0) | 2022.01.23 |
|---|---|
| 머신러닝 | 선형 회귀 알고리즘 (k-최근접이웃 알고리즘과 비교) (0) | 2022.01.22 |
| 혼공단7기 1주차 미션인증 (0) | 2022.01.13 |
| 머신러닝 | 데이터 전처리 | 스케일 조정, 표준화하여 전처리 | 표준점수로 변환 (0) | 2022.01.12 |
| 머신러닝 입문 | 지도학습, train set과 test set (0) | 2022.01.12 |